ComfyUI の ModelSamplingAuraFlow とは何か
ModelSamplingAuraFlow は高解像度画像を生成する際に、ノイズが不足しないようにするノード。
中身は ModelSamplingSD3 ノードと同じ。詳細は SD3 論文の p. 10 Resolution-dependent shifting of timestep schedules を参照。
ノイズを増量することで画像にディティールを追加する使い方もできる。
shift 量の計算
shift 量はベース解像度との比で計算する。SD3 は 1,024px だが Qwen Image は 1,328。
Qwen で 2,048 の画像を生成する場合、n = ベースピクセル数、m = 生成ピクセル数なので sqrt(2048^2/1328^2) ≒ 1.54。ベース shift 量が3の場合、3 * 1.54 = 4.62 が shift 量になる。
HunyuanVideo の場合
HunyuanVideo: A Systematic Framework For Large Video Generative Models の p.13 5.1 Inference Step Reduction によると、経験則では 50 step で生成するなら shift は7、20 step 以下なら shift は 17 にする必要がある。
SD3 論文の p. 10 Resolution-dependent shifting of timestep schedules
高解像度画像はピクセル数が多いので、シグナルを破壊するためにはより多くのノイズが必要になる。

${x_t = \sqrt{\gamma}\cdot x_0 + \sqrt{1-\gamma}\cdot \epsilon : \gamma = 0.7}$
高解像度の画像の情報を破壊するにはより多くのノイズが必要になる
出典:On the Importance of Noise Scheduling for Diffusion Models. Ting Chen. Figure 2
総ピクセル数を $n = H \times W$ とする。ここで単色 c でべた塗された画像を考える。ノイズを付与する拡散プロセスは $z_t = (1-t)c \mathbb{1} + t\epsilon$、ただし $\mathbb{1}, \epsilon \in \mathbb{R}^n$。なので $z_t$ から n 個のランダム変数 $Y = (1-t)c + t\eta$ (ただし、$c, \eta \in \mathbb{R}$ で、$\eta$ は標準正規分布に従う)が観測できる。その期待値は $\mathbb{E}(Y) = (1-t)c$ で、$\sigma(Y) = t$。
c を復元するには $\frac{1}{1-t}\mathbb{E}(Y)$ を計算する。c とサンプリングされた平均 $\hat{c} = \frac{1}{1-t}\sum^n_{i-1} z_{t,i}$ との差は、標準偏差 $\sigma(t,n) = \frac{t}{1-t} \sqrt{\frac{1}{n}}$ になる(なぜなら平均 Y の標準誤差は $\frac{t}{\sqrt{n}}$ なので)。
もし $z_0$ がべた塗り単色画像だと知っている場合、$\sigma(t,n)$ は $z_0$ の不確実性を表現している。幅と高さとを2倍にしたとき、その不確実性は任意の 0 < t < 1 で半分になる。
$\sigma(t,n)$ によって、タイムステップ t と総ピクセル数 n とが不確実性によって対応付けられているので、解像度を変化させたときのタイムステップが計算できる。$t_n$ を総ピクセル数 n のときのタイムステップ、$t_m$ を総ピクセル数が m の時のタイムステップとすると、その不確実性を一致させるには以下の式を満たす必要がある。
\[ \large{ \begin{split} \dfrac{t_n}{1-t_n}\sqrt{\dfrac{1}{n}} &= \dfrac{t_m}{1-t_m}\sqrt{\dfrac{1}{m}} \\ t_m &= \dfrac{\sqrt{\frac{m}{n}}t_n}{1 + (\sqrt{\frac{m}{n}} - 1)t_n} \end{split} } \]この $\sqrt{\frac{m}{n}}$ が ModelSamplingAuraFlow の shift で、3.0 と 6.0 が人間の評価が高かった。
なお上記の式は log-SNR を $\mathrm{log}\frac{m}{n}$ シフトさせる(Hoogeboom et al., 2023):
\[ \large{ \begin{split} \lambda_{t_m} &= 2 \; \mathrm{log} \dfrac{1-t_n}{\sqrt{\frac{m}{n}}t_n} \\ &= \lambda_{t_n} -2 \; \mathrm{log} \; \alpha = \lambda_{t_n} - \mathrm{log}\dfrac{m}{n} \end{split} } \]ただし、$\alpha = \sqrt{\frac{m}{n}}$。
ソース
class ModelSamplingAuraFlow(ModelSamplingSD3) はベースの ModelSamplingSD3 の patch を呼び出しているだけ。
ModelSamplingSD3 の patch の中身は comfy.model_sampling.ModelSamplingDiscreteFlow。
class ModelSamplingDiscreteFlow(torch.nn.Module) で shift が関係しているのは def sigma と def percent_to_sigma で、どちらも shift を time_snr_shift の alpha に入力している。
time_snr_shift の中身は以下のようになっている。
def time_snr_shift(alpha, t):
if alpha == 1.0:
return t
return alpha * t / (1 + (alpha - 1) * t)
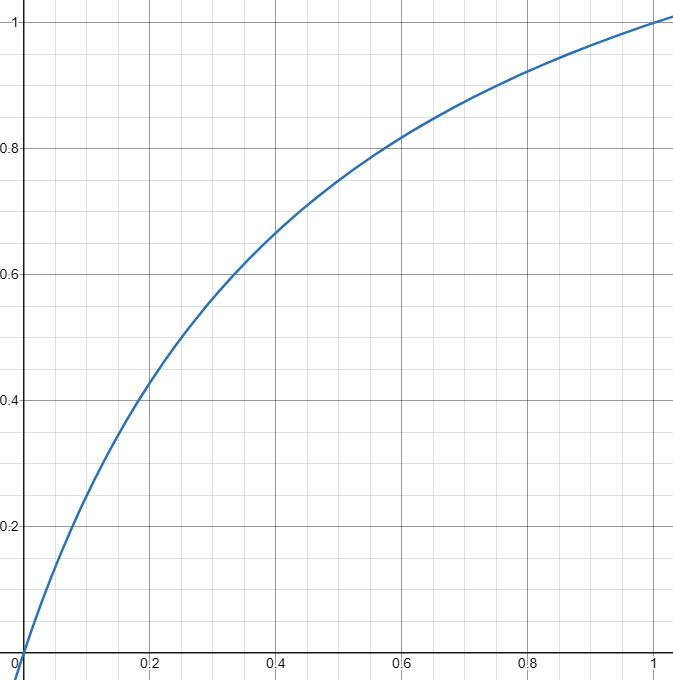
alpha (shift) = 3 の時のタイムステップ t