Waifu Diffusion で効率的に画像を生成する
プロンプトリストはプロンプトやよく検索されているプロンプト(R18)、danbooru タグ検索を参照。
目次
- ワークフロー
- ツールの選択
- Stable Diffusion のモデルリンク
- Stable Diffusion の解説
- Tips
- 上手く描けない場合(胴が長いなど)はアスペクト比を変えてみる
- クオリティタグを使う
- CFG Scale を上げる
- 解像度を上げると頭や体が複数融合する
- Denoising Strength を下げると画質が落ちる
- 細部の修正
- 手の修正
- 手の自由度
- 高解像度化
- 色のコントロール
- 顔に影ができる
- ファインチューニング
ワークフロー
現代的(2025 年)なワークフローは以下のようになる。
- ベースとなる画像を生成する(ChatGPT や MidJourney や NovelAI でもよい)
- ローカルのモデルで以下の工程を一度に実行
- 画風変換
- アップスケール
- 拡張機能の ADetailer のような機能を使って、パーツごとに切り出して i2i
- 細部を手動で修正
上記のようなシンプルなワークフローなら reForge で可能だが、複雑なワークフローや最新モデルが必要なら ComfyUI を使う。
ADetailer で使えるパーツ検出モデルは Civital から探せる。「ADetailer」で検索するか、フィルタの Model > Detection を使うと早い。
素材の編集
以下のモデルが使える。
- ChatGPT
- Gemini 2.5 Flash Image(nano-banana)
- Pixshop AIStudio Google は修正箇所をクリックで指定できる。
- FLUX.1-Kontext
- Qwen Image Edit
2025年8月に発表された Gemini 2.5 Flash Image(nano-banana)は高機能かつ高精度で以下のタスクが実行できる。ローカルで動作させられる Qwen Image Edit 2509 も同様の加工が可能。
- 正面図から3面図を作成
- 線画を変更せずに着色
- 写真から線画抽出
- アップスケール(close-up the face)
- 物体除去
- 物体追加
- 影や照明の変更
- テクスチャ変更
- 複数の入力画像の合成
- 顔を別の画像のものに差し替え
- 表情テンプレート画像と正面画像とから表情差分の作成
- dx8152/Qwen-Edit-2509-Multiple-angles は Qwen Image Edit のカメラアングル制御 LoRA
そのほかの使用例は以下のリンク先を参照。
nano banana
- Claude × Nano Banana Pro で料理漫画を自動生成するパイプラインを作った
- Nano Banana Pro プロンプト検索
- Banana X プロンプトパターン集(インフォグラフィック作例集)
- Awesome-Nano-Banana-images
- 7 tips to get the most out of Nano Banana Pro
- 文字も図解も思いのまま!Nano Banana Pro の凄さと、今すぐ使える活用術
- グーグルの画像生成AI「Nano Banana」は異次元レベル AIコンテンツの作り方を根本から変えた
- Googleの画像生成AI「Nano-banana」をめちゃくちゃ活用できるプロンプトとサンプル画像実例まとめ
- Gemini を使った画像生成(別名 Nano Banana)
- How to prompt Gemini 2.5 Flash Image Generation for the best results
- Geminiの「Nano Banana」で不動産写真の家具を消してみた話
- nano-bananaでモバイルアプリUIモックアップを作る
- nano banana漫画背景生成
- 【Midjourney | Nano Banana】商品撮影のプロが撮影をやめた。誰も教えない、ブランドやECの現場レベルで使える画像生成AIと動画生成AIの神業プロンプトまとめ。
- 画像生成AI「Nano Banana Pro」で判明した“ストーリーボード革命”
- How to Design Magazine Layouts and Covers Using Nano Banana Pro
- Is Nano Banana Pro a Low-Level Vision All-Rounder? A Comprehensive Evaluation on 14 Tasks and 40 Datasets
- Nano Banana can be prompt engineered for extremely nuanced AI image generation
- Nano Banana Pro is the best AI image generator, with caveats
- もう失敗しない。AIで筆文字を書く方法
ChatGPT Image 1.5
Qwen Image
- Qwen-Image-Edit Prompt Guide: The Complete Playbook
- Qwen-Image: Prompt & Parameter Guide
- Simple multiple images input in Qwen-Image-Edit
- Tips for getting the best image generation and editing in the Gemini app
Gemini 2.5 Flash Image(nano-banana)はテキストの画像化は苦手だが画像の文字表現処理はできるので、文字を画像で渡すハックがある。
三面図
動画生成 AI でターンテーブルを作成する方法もある。

Gemini 2.5 Flash Image(nano-banana)
画像のキャラクターの正面・側面・背面から見たキャラクターシートの画像を作成してください。キャラクター間に余白を設定し、キャラクターシートの身長の高さは揃えてください。
英語の場合は Draw that person's three-direction reference sheet.
物体除去

ChatGPT5
ジャケットの柄も削除してしまっている
線画着色
グレースケール画像の彩色は FLUX.1-Kontext を使うと、線画を変化させずに彩色が可能。VRAM 24GB あればローカルでも実行可能。モデルは公開されていないが、リファレンスを参照して線画を着色するモデルの研究として MangaDiT: Reference-Guided Line Art Colorization with Hierarchical Attention in Diffusion Transformers がある。
Gemini 2.5 Flash Image(nano-banana) も線画を変更せずに着色可能。

Gemini 2.5 Flash Image(nano-banana)

髪のベタが一部消えている
背景のアイレベルが低く不自然なので追加の修正が必要
彩色・色変え
ワークフロー終盤の色変えは Photoshop などのツールを使った方がよい。

Gemini 2.5
ポーズ指定
ローカルなら Control Net を使うのがもっとも高性能。

Gemini 2.5 Flash Image(nano-banana)
手の左右が逆だがそれ以外は問題がないレベル

ChatGPT5
ChatGPT5 は精度は低いができなくはないレベル
- 手の左右が逆
- 腰のベルトが片方ない
- 腰の赤いベルトの裏がない
- 腕輪がジャケットの柄と解釈されている
- ジャケットの柄が変更されている
- ジャケットのうさ耳が削除されている
- ジャケットの裏の一部が青になっている
- 胸のひもの終端の形が変更されている。
顔や服を変える

ChatGPT 4o
動画生成 AI で着せ替え
Wan 2.2 のような動画生成 AI も 1 フレームだけ生成すれば着せ替え等も可能。
動画生成 AI を使用した素材生成
- 動画生成 AI で画像1枚からターンテーブル動画を作成
- 必要な部分を切り出してアップスケール・i2i
著作権について
拾ってきた画像で img2img を使った場合、同一性保持権(20条1項)の侵害になる。
作例
ツールは reForge。モデルは WAI-NSFW-illustrious-SDXL の v7.0。
1. ベース画像生成
ベースと画風とでモデルを分けるのは、モデルごとに得意なことが違うからだ。ベース画像を生成するモデルは、構図・ポーズ・背景の上手さ・多様性で選ぶ。

Qwen Image
プロンプト:
The illustration of a blue bikini girl standing with v sign in the beach.
2. ローカルでの変換
画風 LoRA やキャラ LoRA を適用して生成する。ポーズが崩れる場合は Controlnet を使用する。CN-posetest_v2_1 なら手書きの棒人間を認識してポーズを指定できる。
img2img で、拡張機能の ADetailer を使って顔・ビキニ上下・手を加筆した。ADetailer の解像度は顔・ビキニは 1024 x 1024、手は 768 x 768。

プロンプト:
masterpiece, best quality, amazing quality, The illustration of a blue bikini girl standing with v sign in the beach. o-ring bikini, side-tie bikini bottom, pale color, skindentation, thigh ribbon,
ここにアーティストタグを入れる
ネガ:
worst quality, bad quality, worst detail, normal quality, good quality, censored, jpeg artifacts, lowres, bad hands, cropped, blurry, comic, sketch
Resize to 1280 x 1704, Euler a, 50 step, CFG Scale 5, Denoising strength 0.6
プロンプトの調査
作成したい画像に近いイメージの画像を Deep Danbooru に入れてタグを調べる。もしくはどこかからプロンプトを拾ってくる。
AUTOMATIC1111 ならローカルで Deep Danbooru が使える。
手元の画像と似た画像を生成したい場合
Control Net の Reference Only を使う。
補正
顔
Automatic1111 の Extension の After Detailer や Dotgeo(hijack) Detection Detailer は顔を検出して顔を加筆する。
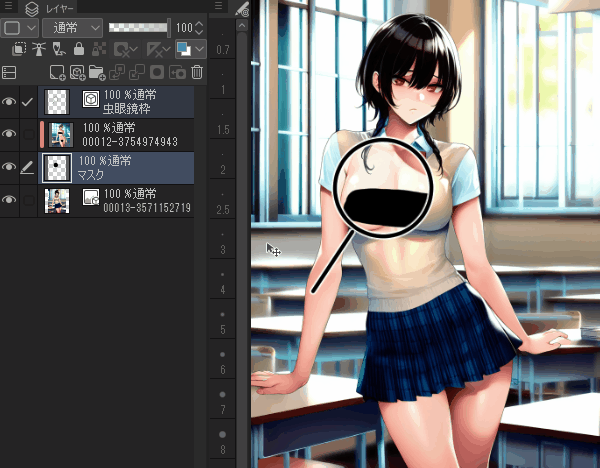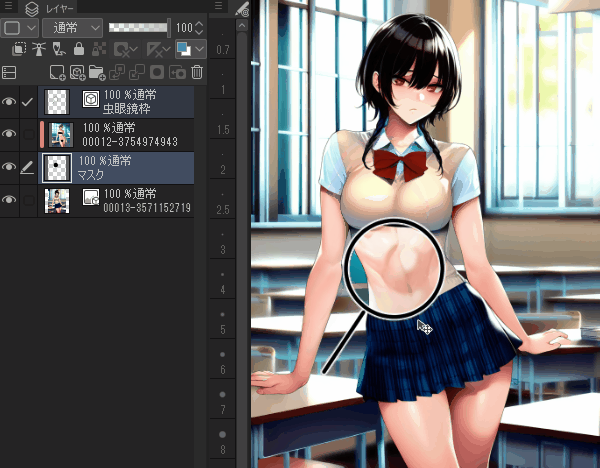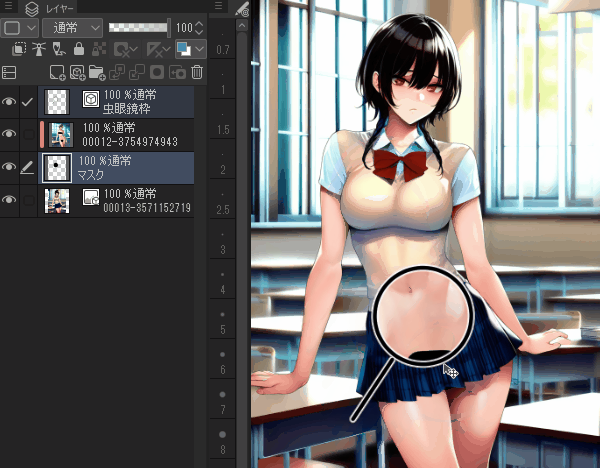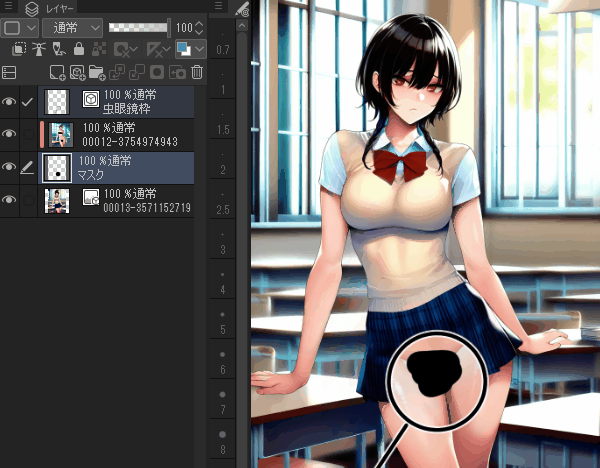
After Detailer の例
After Detailer のプロンプトにのみ highly detailed eyes, glowing eyes, simple highlight を入れる方法がある。

元解像度: 768 x 1024
After Detailer の解像度:1024 x 1024
プロンプト:1girl close up in the classroom
ネガティブ:realistic, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
After Detailer のプロンプト:highly detailed eye, highly detailed face
highly detailed eyes, multicolored eyes, glowing eyes, long eyelashes がよく使われる。
書き込み量
Automatic1111 の Extension の CD(Color/Detail) Tuner は背景の書き込み量を調整できる。
LoRA の detail-tweaker-lora を使う方法もある。ウェイトを -1 にすると画面がシンプルになる。
sd-webui-detail-daemon (ComfyUI-Detail-Daemon)もある。
便利なツール
rembg
AI で背景を透過するツール。
txt2mask
テキストを使ってマスク部分を指定できるツール。
漫画
きらら4コマの描き方(リンク先は AI は無関係)
漫画は構図・アングルが固定されている。キャラの数・位置・向きを指定すれば構図をテキストで指定できる。
キャラの位置はロング(引き)の場合は、背景との関係で簡略化は難しい。アップの場合はパターン化可能。たとえば、キャラ2人いて1人が画面端横向き・もう一人は正面もしくは斜めで発話しているようなコマは大量に出てくる。
キャラの向きは以下の4つでほとんど。
- 正面(正面すこし横)
- 斜め
- 真横
- 真後ろ
より詳細な解説
Nano Banana Pro で ストーリー漫画の作成を試す
絵下手マンがWaifu Diffusionでファンアートを描く方法
続・絵下手マンがWaifu Diffusionでファンアートを描く方法 加筆ノウハウ編
より思い通りの画像を作る!img2img&フォトバッシュ複合ワークフローについて[StableDiffusion]
AI画像生成を利用した着色高速化ワークフロー[NovelAI]
新機能『Depth to image』でベース画像の形状を維持したまま画像生成
実録:AIで描く漫画の実際 ~AIで今風の手描きっぽい漫画を作ってみる
アニメ
AIと3D利用したアニメ制作 統一性のある背景を様々なアングルから生成
AIを活用して簡単なアニメーションを作る方法!一貫性を保ちつつ手軽にキャラクターを動かそう【ControlNet活用術】
差分生成の実例
ControlNet の Canny を使う方法
使用しているツールは reForge。Canny のモデルは bdsqlsz_controlllite_xl_canny.safetensors。ただし anytest の方が性能が良い。
全裸画像を作ってから後から服を着せる方が楽。
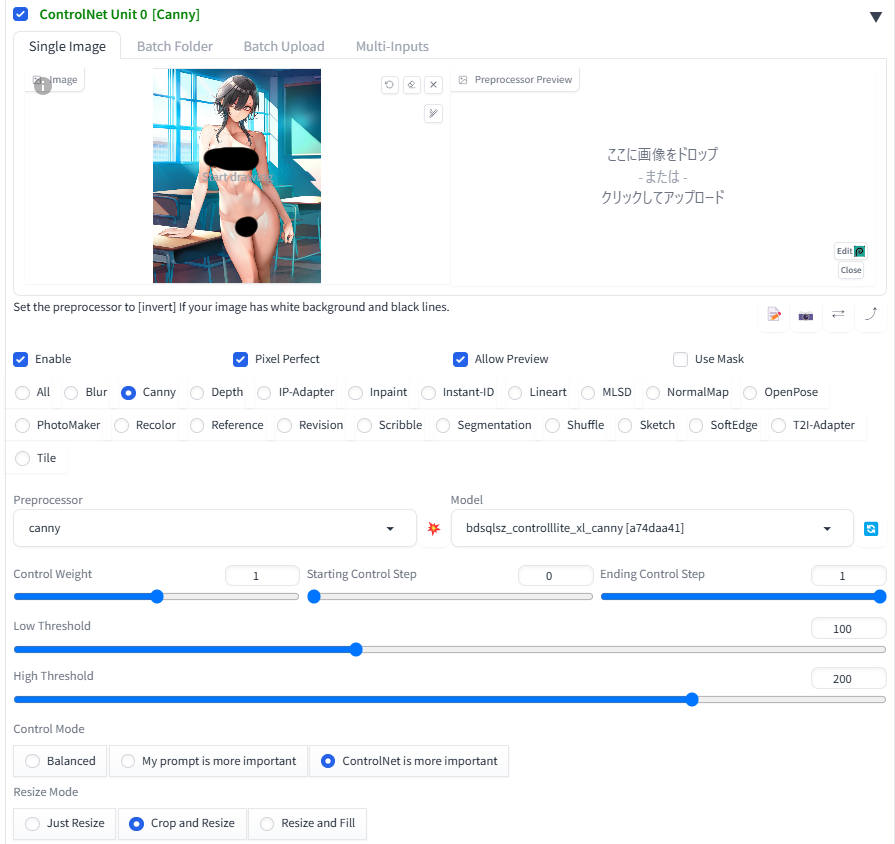
設定例

作成した画像
活用法
表情差分
以下の設定が有効
- Canny
- マスク画像を使う
- シード固定

作例
AUTOMATIC1111 の Prompt S/R を使う方法
プロンプトを切り替えて差分を作成する方法。シードを固定してもポーズや構図が固定できない。場所やシチュエーションを切り替えて、紙芝居的な使い方をするとよい。

モデルは NoobAI XL 1.0
prompt masterpiece, best quality, newest, absurdres, highres, shiny colors, (realistic:0.3), black short hair, standing, school uniform, looking at viewer, 1girl, solo, skinny, (abs:0.4), architecture, school, indoors, desk negative prompt oldest, old, flat color, worst quality, bad quality, normal quality, good quality, thong, lowleg, g-string, lace, jacket, jpeg artifacts, lowres, bad hands, cropped, blurry, comic prompt S/R "solo, ","1other, cellphone, hypnosis, hypnosis app, empty eyes,","1other, cellphone, hypnosis, hypnosis app, empty eyes, undressing, lace-trimmed bra,"
Web で使える Prompt S/R のエディターは Prompt S/R Editor がある。
インペイントで裸画像を先に作る実例
着せたい服がきまっている場合、先に裸画像を作る。そうすると肌のトーンの調整をする必要がなくなる。
ネガティブプロンプトは共通で long body, monochrome, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry

プロンプト例:masterpiece, best quality, 1girl, completely nude in the park, blue archive, genshin
インペイントで下着差分をつくる

インペイント

プロンプト例:masterpiece, best quality, 1girl in the park, blue archive, genshin, underware, bra, panties
インペイントで服差分をつくる

インペイント

プロンプト例:masterpiece, best quality, 1girl wearing a dress in the park, blue archive, genshin
インペイントで服を先に作る実例
生成した画像

seed=214927526
inference steps=15
prompt
bishojo, full body, view straight on, a girl wearing white one-piece with white marble glowing skin and perfect symmetrical pretty face with blush cheeks and light green long hair and glaring eyes on sunny day standing, golden hour lighting, strong rim light, art by krenz cushart and violet evergarden
negative prompt
deformed, bad anatomy, disfigured, mutation, mutated, extra limbs, ugly, fat, missing limb, floating limbs, disconnected limbs,long neck, long body, part of the head, mutated hands and fingers, intricate human hands fingers, poorly drawn hands, malformed hands, poorly drawn face, poorly drawn asymmetrical eyes
マスクと修正した画像
修正画像は描く必要はない。Google 画像検索でそれっぽいのを拾ってきて、張り付けてもいいし、DAZ Studio で作成してもいい。今回は画像を少し拡大している。採用した画像は 20 枚作成したうちの1枚。

マスク

加工した画像

seed=787776388
inference steps=26
denoising strength=0.5
prompt
bishojo, view straight on, a girl wearing luxury lingerie , jewelry, ring, louis comfort tiffany, garterbelt, stocking with white marble glowing skin and light green long hair and glaring eyes on sunny day standing, golden hour lighting, strong rim light, art by krenz cushart and violet evergarden
negative prompt
生成に使ったのと同じ
結果

合成結果
写真を使う場合
使わせていただいた画像は[無料写真] メイド服を着て座る台湾人女性。自撮り画像を使ってもいいし、デッサン人形に服を着せた写真を使ってもいい。3Dなら MMD や VRoid Studio、DAZ|Studio などがある。

入力画像
結果

seed=453989191
inference steps=50
denoising strength=0.55
prompt
view straight on, small breasts, a blonde bishojo wearing a black maid cosplay with white marble glowing skin and perfect symmetrical pretty face with blush cheeks and light green long hair and glaring eyes on sunny day standing, golden hour lighting, strong rim light, art by krenz cushart and violet evergarden
negative prompt
deformed, bad anatomy, disfigured, mutation, mutated, extra limbs, ugly, fat, missing limb, floating limbs, disconnected limbs,long neck, long body, part of the head, mutated hands and fingers, intricate human hands fingers, poorly drawn hands, malformed hands, poorly drawn face, poorly drawn asymmetrical eyes
ツールの選択
以下の3つがよく使われている。
- ComfyUI ノードベースで学習に時間がかかるが他のツールでは作れないような画像加工ができる
- AUTOMATIC1111
- reForge。AUTOMATIC1111 をカスタムして軽量化したもの
Stable Diffusion モデルリンク
最近リリースされたモデルは CIVITAI か huggingface を探せば見つかる。
古いモデルは Stable Diffusion の古い情報に移動した。
XL
Illustrious
タグで版権キャラが出しやすい。年代タグを使うと画風を変化させられる。
Illustrious 派生
NoobAI-XL
Illustrious 派生。使い方は NOOBAI XL Quick Guide や SeaArt Guide NOOBAI XL を参照。
Pony
エロに強いモデル。クオリティタグが特殊。
ドット絵
そのほか
ANIMAGINE XL 3.1 Announcing Animagine XL 3.1
Animagine XL V3 使い方が特殊なので詳細は公式ブログを参照。
モデルマージ
Models, Embeddings, and Hypernetworks
STABLE DIFFUSION MIXING EMPORIUM
階層マージ
Merge Block Weighted - GUI (U-Net のブロックごとにマージ比率を変える)
Safetensor Merger Multi Thread
Stable DiffusionのモデルをU-Netの深さに応じて比率を変えてマージする
sd_merge_numa (マージしてサンプル画像を出力する検証用 Extension)
蒸留モデル
蒸留モデルは少ないステップ数で生成できるが、品質は若干落ちる。また、CFG Scale を下げる必要があるのでネガティブプロンプトの効きが悪くなる。低 CFG でネガティブプロンプトが使いたい場合は NegPip を使う。
ODE サンプラーを使う場合、初期ノイズが決まればデノイズ結果も一意に決まる。ならば初期ノイズから1ステップでデノイズするモデルも理論上作成可能、というのが蒸留モデルの考え方だ。
では最初から蒸留モデルを作成すればいいのではないか、と考えるかもしれないがそれはできない。なぜなら蒸留モデルの学習にはノイズ画像と、ノイズから生成された画像との両方が必要だからだ。DMD2 ではノイズから生成されていない画像も使用して diffusion loss と GAN loss をフィードバックすることにより、教師モデルより高品質な画像生成を可能にした。
DMD2
LoRA の DMD2 を適用すると4ステップ前後で生成できる。
使い方
1. CFG Scale を1に近い値(1.01~1.5 など)にする
CFG Scale を1にするとネガティブプロンプトが使えなくなるので手打ちで CFG Scale を入力する。ただし2未満の CFG はネガティブプロンプトの効きが悪い。低 CFG でネガティブプロンプトが使いたい場合は NegPip を使う。
2. まともに生成できるサンプラーを探す
X/Y/Z plot で上手く描けるサンプラーとスケジューラーの組み合わせを探す。公式は LCM サンプラーを使っているようだ。
たとえば NoobXL 1.0 ε Pred では Sampling Method:DPM++ SDE・Eular a・DDPM・LCM、Schedule Type:Automatic・Uniform・SGM Uniform・Simple・Turbo が相性が良い。Highres fix. を使う場合は CFG Scale を2ぐらいまで上げられるが、色が濃くなる。
3. 調整する
- CFG Scale を変更する。色が濃い・線が太い・画質が悪い場合は CFG を下げる
- LoRA ウェイトを下げ、ステップ数・CFG Scale を増やす。
Hyper SD
Hyper SD は DMD2 同様に高速化する LoRA だ。DMD2 が4ステップ前後で生成するのに対しこちらは8ステップかかる。DMD2 はステップ数を上げると破綻するが、Hyper SD はステップ数を上げて書き込み量を調整することができる。
TDD
TDD は DMD2 より Hyper SD に近い。
Stable Diffusion のパラメーターの解説
CFG Scale
拡散モデルはノイズ画像からノイズを予測し、ノイズ画像から予測ノイズを除去することで絵を描く。
CFG Scale は予測ノイズの強度をスケールするパラメータだ。5~9が適正値で以下のような特徴がある。作例のプロンプト・ネガティブプロンプト・シード値は同じで、違いは CFG Scale とステップ数のみ。
CFG Scale が高い場合
- 画力は上がるが、構図や画風が固定化される
- コントラストが高く、輪郭がはっきりした絵になる
- 少ないステップ数で(20 step 前後)それらしい絵になる。コントラストの高さと明瞭な輪郭線がそう見せている
- 絵が崩壊するリスクが増える

CFG Scale=14, Sampling steps=20
CFG Scale が低い
- ネガティブプロンプトの効果が小さくなる
- 自由な構図や画風を採用し、下手な絵が出力されやすくなる
- コントラストが下がる
- 輪郭がはっきりしない絵になりがち

CFG Scale=3, Sampling steps=100
詳細な解説
CFG Scale は Classifier-Free Diffusion Guidance が詳しい。拡散モデルに追加の classifier ネットワークを追加して同時に学習すると性能が向上するが、classifier のみを分離できず、ネットワークも複雑になる。Classifier-Free Diffusion Guidance ではプロンプトなしのノイズ予測を利用して classifier 利用時と同じような性能向上を実現した。この論文ではプロンプトありのノイズ予測から、プロンプトなしのノイズ予測を引き算している。その結果のスケール量が CFG Scale だ。
Stable Diffusion 1.5 では以下のコードで CFG Scale が使われている。
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2) e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
このコードはプロンプトのみを使ったノイズ予測から、プロンプトを使わないノイズ予測を引き算している。CFG Scale は引き算後の計算結果をスケールするのに使われている。このプロンプトを使わないノイズ予測の部分に描いてほしくないプロンプトを使うというコンセプトがネガティブプロンプトだ。
CFG Scale は単純に予測ノイズをスケールしているだけなので、CFG Scale を低くする場合はステップ数を多くしないとノイズ除去が不十分になる。逆に CFG Scale が高すぎると、ノイズ除去が強すぎて意味のある画像が出力されない。
また数式から、CFG Scale(unconditional_guidance_scale)= 1 の時ネガティブプロンプトの効果がなくなることがわかる。
外部リンク
Classifier-Free Diffusion Guidance
Guiding a Diffusion Model with a Bad Version of Itself
Rethinking Oversaturation in Classifier-Free Guidance via Low Frequency
サンプラー
サンプラーはネットワークが予測したノイズを利用して、ノイズを除去する。ノイズ除去にはいろいろな方法がある。例えば、
- SDE や後ろに小文字の a (ancestral) が付くサンプラーはデノイズ後に残留ノイズを付与するので、絵が変化し続ける
- DPM2 や DPM2S、Heun は2回ノイズ予測を行うので、2倍時間がかかるが精度が良い
- Heun は1回未来のノイズ予測も使う
- DPM2 は 0.5 回未来のノイズ予測も使う
- DPM2S は現在のタイムステップのノイズ予測はデノイズに使わず、1回未来のノイズ予測に使う。デノイズは1回未来のノイズ予測のみを使って行う
- 2M がつくサンプラーは1回前のノイズ情報を保存しておき、それも利用してデノイズする。3M は2回前の情報も使う
- LMS は過去のノイズデータを保存しておいて、重み付けをしてノイズを除去する
- CFG++ は高い CFG Scale で彩度が高くなり、絵が崩壊しがちになるのを修正したもの。ただし CFG Scale を1未満に設定する必要がある。
- SMEA は2ステップごとに1回 1.25 倍に画像を拡大してからデノイズすることで細部の破綻を減らす。SDXL では効果が薄い
- Dy は2ステップごとに1回、ノイズ画像を 1/2 に縮小してデノイズし元のサイズに戻す。これには構図の破綻を減らす効果がある。SDXL では効果が薄い
- Euler Negative は2回に一回画像をネガポジ反転させる。理論的な根拠はない。SDXL では効果が薄い
ODE V.S. SDE
画像が収束するか発散するかは、ノイズ項があるサンプラーかどうか(SDE かどうか)できまる。SDE は名前に SDE や後ろに小文字の a がつく(Euler a や DPM++ 2M SDE など)。それ以外は ODE のサンプラーだ。
ほとんどの SDE サンプラーは ODE サンプラーにノイズを付与しただけだ(Euler にノイズ項を足すと Euler a、DPM++2M にノイズ項を足すと DPM++ 2M SDE)。付与するノイズもすべての SDE サンプラーで同じ。
サンプリングエラー
サンプリングエラーは近似エラーと離散化誤差とがある。SDE と ODE との近似エラーは同じで、ODE に対し SDE は 離散化誤差が大きいにもかかわらずサンプリングの品質がよい。この理由は SDE のノイズ付与がエラーの蓄積を縮小するからだ。
サンプリングエラーの合計は、今までのエラーの蓄積+新しくサンプリングする際のエラーだ。SDE のサンプリングエラーの合計が ODE よりも小さくなる理由は、ノイズ付与による離散化誤差の増加よりも、ノイズ付与による今までのエラーの蓄積を縮小する効果が大きいからだ。
SDE サンプラーのサンプル回数
サンプル回数が多いとステップ1回にかかる時間が長くなるが、その分ステップ数は小さくできる。
1回
- Euler a
- DPM++ 2M SDE
- DPM++ 3M SDE
2回
- DPM++ SDE
- DPM++ 2M SDE Heun
- DPM2 a
- DPM2S a
Restart サンプラー
Restart サンプラーは ODE と SDE の良いとこどりをしたもの。SDE は毎ステップノイズを付与していたが、サンプリングエラーが蓄積していないサンプリング前半にノイズ付与をやっても意味がない。これは計算の無駄が多く、画質にも影響がある。
Restart サンプラーはサンプリングエラーの蓄積した中盤に最大2回ノイズを付与する。ノイズを付与する際に σ の再サンプリングを行い、少し前(現在の σ + 2)の σ からやり直す所が特徴的な部分だ。
Restart はサンプラーではなくサンプリングフレームワークなので、本来なら任意の ODE サンプラーが選択できるが、Automatic1111 の実装では Heun か Euler になる。デフォルトは second_order が True なのでデノイズに Heun が使われる(False の場合は Euler)。
Restart のスケジューラー
Restart サンプラーはスケジューラーに karras が強制される。
ステップ数とリスタート(ノイズ付与)回数
- 19 以下:0回(UI で指定したスケジューラーが使われる)
- 35 以下:1回(スケジューラーは karras 強制)
- 36 以上:2回(スケジューラーは karras 強制)
ステップ数 20 回の場合、ステップ 10 の時に1回ノイズ付与が行われる。ステップ数 35 の場合は、ステップ 23 の時に1回ノイズ付与が行われる。
ステップ数 36 回の場合、ステップ 16 の時とステップ 25 の時とに、2回ノイズ付与が行われる。
外部リンク
Restart Sampling for Improving Generative Processes
LCM
普通のサンプラーはノイズ画像とデノイズ結果とをブレンドしてデノイズしていく。しかし LCM は元のノイズ画像をブレンドするのではなく、デノイズ結果に元のノイズ画像に相当するノイズ量を新たに付与する。SDE と違い LCM は付与するノイズ量が多い。
サンプラーの選択
サンプラーの選択については Understanding Stable Diffusion Samplers: Beyond Image Comparisons が詳しい。
しかし現在ではモデル制作者が推奨のサンプラーを指定することが多いので、それを使う。
外部リンク
Understanding Stable Diffusion Samplers: Beyond Image Comparisons
Stable Diffusion Samplers: A Comprehensive Guide
Sampler Scheduler for Diffusion Models
CFG++: Manifold-constrained Classifier Free Guidance For Diffusion Models
DDPM, DDIM, SDE のサンプラーや拡散モデルの解説は Diffusion Models: Tutorial and Survey が詳しい。
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
k-diffusion/k_diffusion/sampling.py
UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models uni_pc.py
スケジューラー
スケジューラーは各タイムステップでのデノイズ量をきめる。具体的にはタイムステップを、除去するノイズ量を決定する σ に変換する。実際は σ の勾配がデノイズ量をきめている。
Automatic を選択した場合はモデル内臓の σ テーブルが使われる
SGM Uniform は設定で sigma_max や sigma_min を変更しない限り、Uniform と同じだ。Polyexponential も関数のパラメータを変更しない限り Exponential と同じ。
σ とデノイズ量との関係
デノイズ量は σ の傾きで決まる。σ の傾きが水平に近いほどデノイズ量は小さい。σ の傾きが水平に近いとき、以下の式の σi+1/σi は1に近くなる。
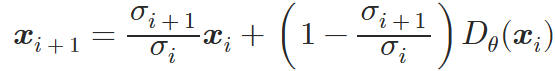
Euler サンプラーの数式
この数式では Dθ(xi) はデノイズ後の画像
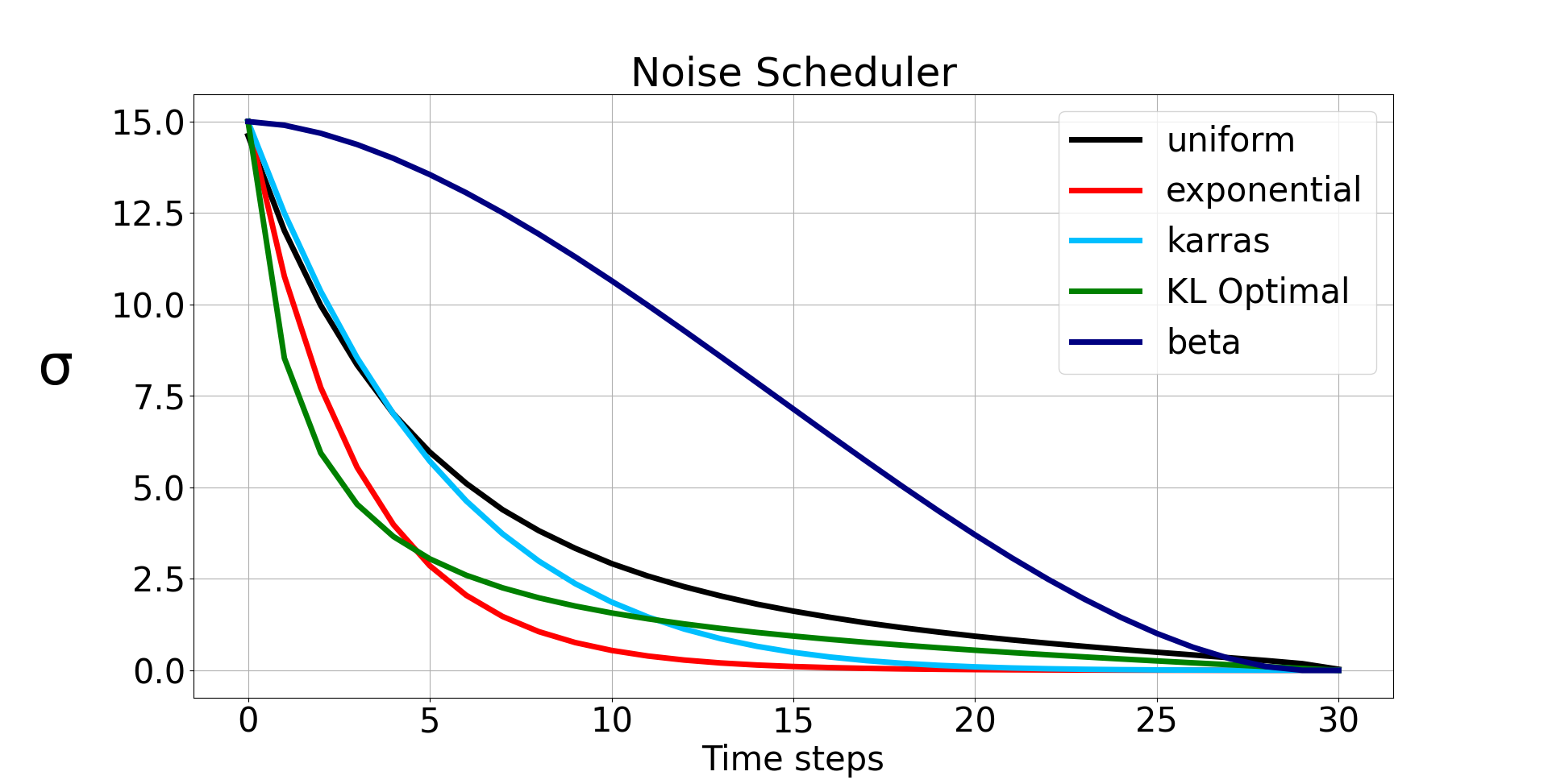
Step=30 のときの σ の変化
このグラフでは低いタイムステップで強くデノイズがかかっているように見えるがそうではない
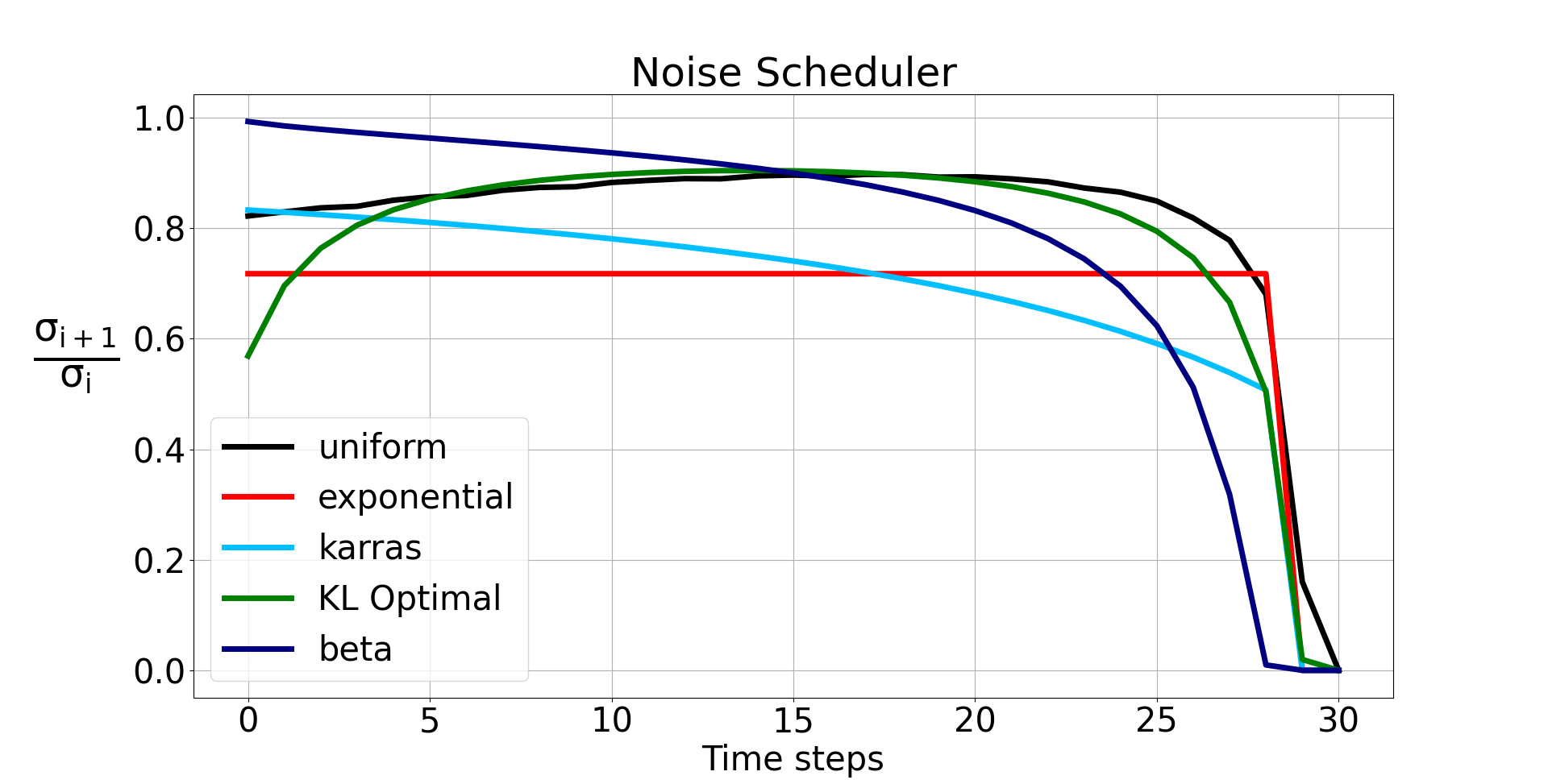
Step=30 のときのデノイズ量の変化。1に近いほどデノイズが弱い
外部リンク
KL Optimal Align Your Steps : Optimizing Sampling Schedules in Diffusion Models
On the Importance of Noise Scheduling for Diffusion Models
シード
拡散モデルはノイズ画像からノイズ除去を繰り返すことで絵を描く。その初期ノイズの乱数パターンを指定する。シードを固定しても、解像度を変更すると絵は大きく変わる。
Denoising Strength のアルゴリズム
img2img
バッチカウントとバッチサイズ
小さい画像サイズでプロンプトの調整をする場合は、バッチサイズを最大にすると速い。
バッチカウントは画像の生成枚数。バッチサイズは並列生成する枚数だ。最終的な生成枚数はバッチカウント×バッチサイズになる。
バッチサイズは余計に VRAM を消費するが生成は速くなる。RTX 3050 で 384x512 のサイズの画像を作成する場合、以下のような結果になった。
| バッチカウント | バッチサイズ | 生成にかかった時間(秒) | VRAM 使用量(GB) |
|---|---|---|---|
| 8 | 1 | 15 | 4.1 |
| 1 | 8 | 10 | 5.1 |
| 16 | 1 | 31 | 4.1 |
| 1 | 16 | 19 | 5.9 |
GPU の種類と画像生成時間
VRAM で生成できる解像度の上限が決まるので、VRAM で GPU を選ぶ。最低ラインは 12 GB。8GBでも生成なら問題ないが、将来性に不安がある。
【Stable Diffusion】AIイラストにおすすめなグラボをガチで検証【GPU別の生成速度】
NovelAI 5ch Wiki#結果一覧も情報が多い。
Tips
上手く描けない場合はアスペクト比を変えてみる
1:1のアスペクト比で上手く描けない場合は、縦長や横長にすると上手く描ける場合がある。人物は縦長の方が形が崩れにくい。船は横長だと上手く描ける。
胴長になる場合は、高さの解像度が高すぎる。高解像度にしたい場合は、丁度良いバランスの解像度で生成し、 hires. fix を使う。
身体が切られる場合は映す部位の指定する
顔に注目させたいなら face close-up。
膝や脚まで入れるなら head to knee や head to leg。
バストアップなら breast。
上半身なら upper body。
膝より上の場合なら "full body, thigh" をプロンプトの先頭に持ってくる。
すねも入れるなら "full body, legs" をプロンプトの先頭に持ってくる。
足も入れるなら "leg line" や "full body, shoes" をプロンプトの先頭に持ってくる。
クオリティタグを使う
モデルによっては masterpiece, best quality, score_9 などのクオリティタグが存在する。プロンプトでそれらを指定することで、クオリティを上げられる。
CFG Scale を上げる
CFG Scale を上げると簡単に画力を上げられるが、ポーズや構図がありきたりになる。上げすぎるとコントラストや彩度が高い、くどい絵になる。
解像度を上げると頭や体が複数融合する
AUTOMATIC1111 の Highres. fix を使う。
細部の修正
Automatic1111 の Variations を使う
シード横の Extra にチェックを入れると使える。弱いノイズを追加しちょっと違う絵を出力する。
つまり、シードを固定し、細部が治るまで Variations シードガチャをする。
手動修正
AUTOMATIC1111 の拡張機能の ADetailer 等はこの項目の工程をすべて自動化してくれる。
Stable Diffusion (Waifu Diffusion)は細部が崩れやすい。全身が入る構図だと確実に顔が崩れる。なので、細部の修正に inpaint を使うのは意味がない。細部を修正する場合は inpaint を使うのではなく、以下のように自力で合成する。
- 適当なペイントソフトで修正したい部分を切り出して 512px * 512px に拡大
- 切り出した画像を img2img に入力して、同じプロンプトで再度画像を生成
- 生成した画像をペイントソフトで縮小して合成

元画像
extremely detailed CG unity 8k wallpaper of a loli girl with silver long wavy hairstyle and white marble glowing skin and perfect symmetrical pretty face with blush cheeks and glaring red eyes, wearing fantasic dress with many frills, standing in the baroque architecture, art by krenz cushart and violet_evergarden, golden hour lighting, strong rim light, intense shadows, bokeh
seed=246225998

切り出して加筆した画像

生成された画像(10枚作成した内の1枚)

合成結果
手の修正
Waifu Diffusion (Stable Diffusion)は手が上手く描けない。この対策は2つある。ひとつはネガティブプロンプトを使う方法で、もうひとつは自分の手を使う方法だ。
自分の手を使う方法
自分の手をスマホで撮影して、手の部分を切り出して出力画像に張り付ける。その加工した画像を img2img に入力する。
Clip Studio Paint で手の3Dオブジェクトを使う方法がある。
手の自由度
手の自由度低いポーズは上手く描ける。例えば skirt hold, skirt lifted by self, spread pussy, double v など。
高解像度化
AUTOMATIC1111での高解像度化は以下の方法が高品質だ。
- Highres fix でマシンが生成できるの最大解像度で生成する
- アップスケーラーで高解像度化する
高解像度化手法
高解像度化には2つの方法がある。アップスケーラーを使う方法と、アウトペインティングを使う方法とだ。
アップスケーラー
アップスケーラーは AI を使って画像を拡大する。
アウトペインティング
アップスケーラーと違い、アウトペインティングはすでに作成した画像に追記して拡張する。アウトペインティングは AUTOMATIC1111 で使える。
色のコントロール
AI が色の指定を無視した場合に、色を修正する方法は5つある。
- ペイントアプリで編集する
- インペイントで編集する
- CFG Scale を上げる
- AUTOMATIC1111 の Prompt Editing を使う
プロンプト
プロンプトで出力を詳細に制御するのは不可能だ。img2img を使って画像を加工する方がはるかに早い。今後も Stable Diffusion を使うつもりがあるならば、板タブか液タブを買って、基本的な画像編集ができるようになった方がいい。
ネガティブプロンプトはとても強力だ。『描いてほしくないもの』を指定することで効率的な絞り込みができる。
Danbooru タグ列挙法は Stable Diffusion の古い情報 に移動した。
テキスト生成AIを使う方法
ChatGPT、Bingによるプロンプトの生成・変換(NyaFuさんバージョン)
プロンプトの探し方
- 外部のプロンプトリンクを見る
- 画像を Deepdanbooru に入れる。Deepdanbooru は AUTOMATIC1111 からも使える
- PNG file chunk inspectorで AI 製の画像にプロンプトが埋め込まれていないか調べる
- Lexica でほかのユーザーが作成したプロンプトを調べる
- PixAI.Art で調べる。
- chichi-pui
danbooru
danbooru は日本語で検索できる。
外部のプロンプトリンク
I USE STABLE DIFFUSION USING DANBOORU/WAIFU MODEL (ビクトリア朝油彩)
中国語
ツール
プロンプトジェネレーター
NovelAI Tag Generator。右クリックして翻訳できる。
NovelAIのプロンプトを管理・調整するChrome拡張を作りました
タグ調査
Deep Danbooru
アップロードした画像の Danbooru タグを教えてくれる。
メタデータ閲覧
画像が AUTOMATIC1111 で作成された場合、プロンプト等の情報は画像ファイルに埋め込むこともできる。画像があればプロンプト等が公開されていなくてもこれで確認できる可能性がある。
clip-interrogator
画像からプロンプトを推測するツール。AUTOMATIC1111からも使える。
DeepL
日英翻訳。日本語で書いた文章を翻訳して、そのままプロンプトに入れる。
Lexica
テキストから、他の Stable Diffusion のユーザーが作成した画像を調べられる。
NovelAI Prompt整理ツール
スプレッドシートを使ったプロンプト管理ツール。
Stable Diffusion Prompt Generator
プロンプトを入力すると、アーティストや場所やライティングのプロンプトを追加してくれるジェネレーター。
クオリティタグ
モデルによっては masterpiece, best quality, score_9 などのクオリティタグが存在する。プロンプトでそれらを指定することで、クオリティを上げられる。
クオリティタグは学習素材の不足が原因で使われている。モデルの学習には大量の画像が必要で、masterpiece の画像だけでは学習するのに不十分だ。より少ない学習画像で学習できる方法が見つかれば、クオリティタグは不要になるかもしれない。
ワードのウェイト
プロンプトの語順は前のほうが影響力が強く、後ろの方の語は無視されやすい。
無視してほしくない語は繰り返すのが有効。たとえばショートケーキを出したければ、"strawberry shortcake, tiny golden puppy eating strawberry shortcake” とする。これが単に "tiny golden puppy eating strawberry shortcake" だと、ショーケーキが無視されて苺だけが出現したりする。
AUTOMATIC1111 のウェイト
AUTOMATIC1111は () でポジティブなウェイト、[] でネガティブなウェイトをつけられる。() や [] は重ねると強調される。後ろの方のプロンプトは無視されがちなので、その対策によく使われる。
a girl with [silver] hair and (blue eyes:1.2)
ウェイト V.S. 位置
ウェイトよりプロンプトの位置の方が影響力が強い。なので画風の影響力を小さくしたい場合は、画風やアーティストタグをウェイトだけ調整するのではなく、プロンプト後方へ配置するとタグの影響力を制御できる。
文字通りの ()
AUTOMATIC1111 では "\(\)" で文字通りの () が入力できる。文字通りの () は danbooru タグで名前の衝突を解決するときによく使われる。
- pokemon \(anime\)
- pokemon \(creature\)
- dakimakura \(medium\)(ベッドで寝ている画像を出したいときによく使う)
- dakimakura \(object\)(普通の抱き枕)
- masturbation \(female\)
- masturbation \(male\)
参考リンク
SD GUIDE FOR ARTISTS AND NON-ARTISTS IN-DEPTH TIPS, TRICKS, TUTORIALS AND MORE
プロンプトのトークンについて
プロンプトは最長で 75 トークン。1単語1トークンとは限らない。
Stable Diffusion のテキストエンコーダーは大文字小文字を区別しない。
Stable Diffusion のテキストエンコーダーの語彙は3万語程度。
プロンプトのトークン制限
プロンプトのトークン数の制限は、使用しているテキストエンコーダーに依存する。Stable Diffuison は 75 トークンが上限になる。
この制限がないツールはプロンプトを分割してトークンに変換した後、トークンをマージすることでこの制限を回避している。なので文の途中でプロンプトが分割されると、意図しない出力になる。AUTOMATIC1111 では BREAK を入れると任意の位置でプロンプトを分割できる。
外部リンク
Stable Diffusion Akashic Records
ネガティブプロンプト
ネガティブプロンプトも通常のプロンプト同様に 75 トークンまでしか認識しないが、トークンマージによって制限を回避しているツールもある。
使用例
たとえば目を閉じさせたいとする。closed eyes をプロンプトに指定しても目を閉じない場合に、open eye をネガティブに入れる。
言外の意味(connotation)の除去にもネガティブプロンプトは使える。たとえば blonde は女性の金髪という意味を持っている。blonde から女性の意味を除去するにはネガティブプロンプトに woman や girl を入力する。
ショーツを途中まで脱がせる panty pull という言葉がある。しかし panty pull には panty が含まれるので、二重にショーツをつけている絵がよく出力される。プロンプトに panty pull を指定し、ネガティブに panties を指定することで、二重ショーツ問題に対処できる。
線画の着色にもネガティブプロンプトが使える。ラフを img2img するさいに monochrome をネガティブにすると線画に色をつけてくれる。ただし確実ではないので下塗りをした方がいい。
注意点
ネガティブプロンプトはプロンプトとして入力しても効果のあるものでないといけない。たとえば danbooru タグで訓練されたモデルで、データが 90 程度しかない missing finger をネガティブプロンプトに入れてもその効果はない。
具体的には、プロンプトに red hair を入れて髪が赤くなるなら、ネガティブプロンプトに red hair を入れても効果がある。
ネガティブプロンプトは予期しない画質や画風の変化が起こることがある。なので、プロンプトや extension で解決できない問題のみをネガティブプロンプトで解消するようにした方がいい。
ネガティブプロンプトの実装
ネガティブプロンプトは CFG Scale と関連が深い。もともとの CFG Scale はプロンプトなしのノイズ予測を使用して、性能を向上するテクニックだった。そこで、プロンプトなしのノイズ予測ではなく、描いてほしくないプロンプトのノイズ予測を利用したのがネガティブプロンプトだ。
ネガティブプロンプトはプロンプトを引き算しているのではない。プロンプトのみを使って予測したノイズとネガティブプロンプトのみを使って予測したノイズとを引き算している。引き算した結果は CFG Scale でスケールされるが、詳細は CFG Scale を参照。
人体に関する汎用ネガティブプロンプト
以下のネガティブプロンプトを入れると画力が上がる。
Novel AI のデフォルトネガティブプロンプト
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
全体
bad art, ugly, messy drawing, flesh pile
flesh pile=蓮コラ。
身体・手足
deformed, bad anatomy, disfigured, mutation, mutated, extra limbs, fat, obese, missing limb, floating limbs, disconnected limbs, long neck, long body, part of the head, poorly drawn feet, mutated skeleton, long skeleton, bad proportions, 2girls, snuggled, dismemberment
変な場所から手や脚が生えるのは 2girls や 3girls、snuggled をネガティブに指定する。
分詞形(deformed や mutated、drawing など)は2トークン消費する。
手・指
mutated hands and fingers, intricate human hands fingers, poorly drawn hands, malformed hands, bad hands
顔
poorly drawn face, poorly drawn asymmetrical eyes, big ears, mutated face
nose:鼻を点で描いた画風になりやすくなる。
head out of frame :顔の大部分が切られる場合
smile, happy, pleasure:目のハイライトを消す
無表情
troubled eyebrows, blush, smile, happy, pleasure:無表情を作りたいときに
open mouth, teeth:口を閉じさせたいときに
エルフ耳
sharp ears, pointy ears, animal ear
乳首
extra nipples
巨乳
tits, huge breast
横乳
sideboob
画風に関するネガティブプロンプト
リアル風・3DCG風
portrait, portrait face は Danbooru のタグにないので、これを入れるとリアル風の画風を抑制してくれる。
portrait, portrait face, doll, photo face, Korean face, Asian face, African face
octane render, 3d, unity, unreal, maya :3DCG風になる場合、octane render は特に効果がある。
アニメ・イラスト風
anime, comic, manga :リアル寄りにしたい場合
カートゥーン
western
ボケ
blurry, blur, out of focus, bokeh, fog
平坦な色使い
flat shading, flat color:画面が華やかになる
グレー
grayscale, black&white, monochrome :カラー画像を出力したい場合。漫画からデータを拾ってくるとよくグレーになる。
文字
text, text title signature
漫画の吹き出し
speech bubble
コマが割られる
multiple views, comic, manga, split screen
アーティスト
変な絵を描くアーティストをネガティブに入れておくと変な絵は出にくくなる。
(pablo picasso), (H.R. Giger), (Gustave Dore), (Chaim Soutine), (Flora Borsi), (vincent van gogh), (paul gauguin), cubism
複数人生成する場合
1girl, solo, symmetrical
symmetrical が入っているのは、全員が正面顔でこちらを見ている絵が出ないようにするため。
yiffy モデルでケモ成分をおさえる
animal, furry
AUTOMATIC1111 の Prompt Editing
Prompt Editing は画像生成の途中でプロンプトを変更する機能だ。Prompt Editing を使うと通常では不可能な表現が可能になる。たとえば "a girl [wearing a onepiece:naked:0.5]" とすると、服が透けている表現になる。これはステップ数が 50 とすると、最初の 1~25 ステップは "a girl wearing a onepiece" を実行し、26~50 ステップは "a girl naked" を実行する。
- [smile:sad:0.5] として表情をブレンドすることも可能。
- "[white::0.5] hair, [:red:0.5] eye" などで色移り対策
- [octane render::0.5] や [photo::0.5] で実写とイラストをブレンド
- [watercolor::0.5] で水彩の強さをコントロール
- [cloth:naked:0.5] で透けを表現できる
- [no wearing:wearing blue dungarees:0.1] や "naked,[:((blue)) Dungarees:0.3]" で裸オーバーオール
- [cheerleader:0.2] ポンポンが消えやすい
色のコントロール
Prompt Editing
黒いドレスと銀髪の例
- [black dress:((((white silver)))) hair:0.8]
- [black:0.8] dress and [((((silver)))):0.8] hair
Regional Prompter
Automatic1111 の Extension の Regional Prompter はプロンプトの効く領域を指定できるので、これで対策することもできる。
BREAK
プロンプトに BREAK を入れると、プロンプトが分割される。色ごとにプロンプトを分割すると色移りしづらくなる。
顔に影ができる
2つ方法がある。
- レフ板 LoRA を使う
- (backlighting:1.3), (underlighting:1.3) で露出アンダーにした後で、ツールで明るさを持ち上げる(トーンカーブで赤をすこし持ち上げる)
Stable Diffusion のプロンプト Tips
何も指定しない(たとえば "a kawaii girl")と平面的な絵しか出てこない。なのでディティールの足りない部分を見つけて、プロンプトに追加していく必要がある。
プロンプトの語順は前のほうが影響力が強く、後ろの方の語は無視されやすいので、複数の色を指定するプロンプトは制御しづらい。たとえば "a loli girl with long white hair wares pink dress and blue shoes." のようなプロンプトでは青い靴は無視されがちになる。青い靴を文頭に持ってくると、服や髪が青くなったりする。
語には言外の意味(connotation)が含まれる。たとえば blonde は金髪だけではなくて、女性にたいして使われることが多い。blonde から女性の意味を除去するにはネガティブプロンプトに woman や girl を入力する必要がある。
2つのオブジェクトを融合するのに as が使える。たとえばヨーダのようなガンジーを描くには "ghandi as yoda" にする。
人物を作成するには、プロンプトに以下の5つの要素を入れるといい。ただしプロンプトの語順は前のほうが影響力が強いので、背景より人物が重要な場合は、人物を先に描写する必要がある。背景を先に描写してしまうと人物をどれだけ詳細に書いても無視されることがある。逆に人物を先に描写するとポートレート風の画像がよく作成される。
- 天気・時間帯
- 場所・背景
- 人
- カメラ
- 作風・アーティスト名
色
色に関する Danbooru タグは tag group:colors を参照。
- light (明るい)
- dark (暗い)
- pale (薄い)
- deep (濃い)
ポストエフェクト
- blurry background (後ボケ)
- blurry foreground (前ボケ)
- chromatic aberration (色収差)
- depth of field (被写界深度)
- lens flare (レンズフレア)
- film grain (フィルムグレイン)
- bokeh (ボケ)
- perspective (パース)
- fisheye (魚眼)
- diffraction spikes (光条)
- faux traditional media (アナログ風)
- caustics (コースティックス)
- vignetting (周辺減光)
- double exposure (二重露光)
- backlighting (逆光)
- underlighting (露出アンダー)

プロンプト
masterpiece, best quality, amazing quality, 1girl, solo, blurry background, blurry foreground, chromatic aberration, depth of field, lens flare, backlighting, film grain, bokeh, perspective, diffraction spikes, faux traditional media, vignetting
天気・時間帯・ライティング
- 明るい
- bloom
- 夕暮れ・朝焼け
- dawn (夜明け)
- sunrise (朝焼け)
- twilight (夕暮れ)
- sunset (夕焼け)
- dusk (黄昏)
- golden hour lighting
- ダイナミック
- backlighting
- strong rim light
- intense shadows
- overexposure (露出オーバー・コントラスト高めになる)
- 暗め
- underlighting
- midnight lighting
- in the rain
- rainy days
- cloudy
- sidelighting
場所・背景
プロンプトに architecture と入れておくだけでも背景のクオリティが上がる。
背景にこだわりがない場合、beautiful landscape と書いておくといい感じにしてくれる。bokeh や soft focus などの語で背景をぼかすのも可。季節を表す語は最後においても結構効果があるのでおすすめ。
背景の拡張に Photoshop のジェネレーティブ塗りつぶしが使える。
建物
- architecture
- ancient egyptian architecture
- east asian architecture
- european architecture
- gothic architecture
- greco-roman architecture
- mesoamerican architecture
- middle eastern architecture
- in misty onsen (温泉)
- by the moon (月)
- in a bar, in bars (バー)
- in a tavern (居酒屋)
- in a locker room (ロッカールーム)
- infirmary (保健室)
- factory (工場)
- rooftop (屋上)
- in the chainging room, vanity table (更衣室、洗面台)
- fashion show
- alley (裏路地)
- air conditioner (室外機)
- industrial pipe
- trush can
- drainpipe
- trash bag
- graffiti (壁の落書き)
- street
- against wall
- brick wall
- power lines
- neon lights
- against wall (壁)
- 公共
- alleyway (隘路)
- in the street (道路)
- central park (中央公園)
- in the cyberpunk city (サイバーパンク)
rainy night in a cyberpunk city with glowing neon lights - lighthouse (灯台)
- Japanese arch (鳥居)
- cityspace (都会)
- power lines (電柱)
- residential area, road (居住区)
- junction, intersection(交差点)
- ヨーロッパ
- temple (神殿。inside temple で神殿内部)
- greece temple (ギリシャ神殿)
- in the baroque architecture (バロック建築)
- in the romanesque architecture streets (ロマネスク建築)
- palace (宮殿)
- at the castle (城の外観が背景)
- in the castle (城の内部が背景)
- chapel (礼拝堂)
雲
- cumulonimbus cloud (入道雲 積乱雲)
- cloudy sky (空がほとんど雲)
- overcast (空が完全に雲)
- dark clouds
- above clouds
- fallstreak hole (雲の穴)
- contrail (飛行機雲)
- distrail (飛行機が雲を切断)
- flying nimbus (金斗雲)
山
- on a hill (丘で)
- the top of the hill (山頂で)
海
- on the beach
- over the sea
- beautiful purple sunset at beach
- in the ocean (海中にいる)
- on the ocean (船か何かの上にいる)
- luxury pool
平地
- grassfield
- in a meadow (牧草地)
- plateau (台地)
- on a desert (砂漠)
- riverbank (土手)
季節
- in spring
- in summer
- in hawaii
- in autumn
- in winter
ダーク
- bloodborne
- dark soul
- abandoned school (廃墟の学校)
ファンタジー
- granblue fantasy
- octopath traveler
- medieval european city
- medieval european market
日本
- fireworks (花火)
- torii (鳥居)
- shrine (神社)
- shide (四手)
- gohei (御幣。博麗霊夢が持っている棒みたなやつ)
- oonusa (大幣)
- stone lantern (石灯籠)
- paper lantern (提灯)
- sky lantern (天灯。中国、タイ、ポーランドでよく使われる)
- donation box (賽銭箱)
- temizuya (手水舎)
- ema (絵馬)
- omikuji (おみくじ)
- omainu (狛犬)
- ramen shop
- stone walkway
- stone stairs
- bamboo broom (竹箒)
- tatami
- shouji
- school gym (体育館)
- gym storeroom (体育倉庫)
- electric fan (扇風機)
- uchiwa, paper fan (うちわ)
- noren (のれん)
- hachimaki
- yatai
食べ物
- mcdonald's (マクドナルド)
- starbucks (スタバ)
- stew (シチュー)
- walnut (クルミ)
- omelet (オムレツ)
- sauce
- soy source
- ketchup
- egg \(food\)
- fried egg (目玉焼き)
- boiled egg
- fast food
- burger (ハンバーガー)
- hot dog (ホットドッグ。dog をネガティブ)
- pizza
- california roll
- sandwich
- drink
- soup
- soda
- beer
- alcohol
- coffee
- 海産
- ikura \(food\)
- shark
- salmon (鮭)
- fish \(food\)
- eel (うなぎ)
- shrimp (エビ)
- crab (カニ)
- lobster
- crayfish (ザリガニ)
- hermit crab (ヤドカリ)
- barnacle (フジツボ、エボシガイ)
- caviar (キャビア)
- nori \(seaweed\) (海苔)
- scallop (ホタテ貝)
- bread (パン)
- loaf of bread
- croissant (クロワッサン)
- baguette (フランスパン、バゲット)
- meat (肉)
- barbecue
- yakiniku
- chicken \(food\)
- fried chicken
- chicken nuggets
- steak (ステーキ)
- kabab (ケバブ)
- bacon (ベーコン)
- sausage (ソーセージ)
- dessert (デザート)
- cake
- chocolate cake
- cake slice
- chiffon cake (シフォンケーキ)
- cup cake
- strawberry shortcake
- swiss roll (ロールケーキ)
- tart \(food\) (タルト)
- fruit tart
- waffle (ワッフル)
- doughnut (ドーナツ)
- jam (ジャム)
- toast (トースト)
- chocolate cornet (チョココロネ)
- melon bread (メロンパン)
- cookie (クッキー)
- checkerboard cookie (黒と白の四角いクッキー)
- thumbprint cookie (中央にジャムか何か塗っているクッキー)
- butter (バター)
- honey (はちみつ)
- castella \(food\)(カステラ)
- candy, lolipop
- ice cream
- sundae, parfait (サンデー、パフェ)
- popsicle (アイスキャンディー、棒アイス)
- scone (スコーン)
- mousse \(food\) (ムース)
- mont blanc \(food\) (モンブラン)
- cream puff (シュークリーム)
- whipped cream (ホイップクリーム)
- chocolate syrup (チョコシロップ)
- wafer stick (ウェハース)
- dorayaki
- red bean paste (あんこ)
- anmitsu \(dessert\) (餡蜜)
- souffle pancake (スフレパンケーキ)
- konpeitou
- vegetable (野菜)
- salad (サラダ)
- tomato
- onion
- garlic
- broccoli (ブロッコリー)
- carrot (人参)
- cucumber (キュウリ)
- lettuce (レタス)
- eggplant (茄子)
- corn
- potato
- mint
- 日本
- matcha \(food\) (抹茶)
- rice ball
- onigiri (おにぎり、おむすび)
- ramen, noodle (ラーメン)
- cup ramen
- tempura
- sushi
- conveyor belt sushi (回転ずし)
- tofu
- mochi (モチ)
- baozi (饅頭、包子、中華まん)
- sake (日本酒)
- yakitori (焼き鳥)
- bento (弁当)
- osechi
- pocky
- wagashi (和菓子)
- kamaboko
- udon
- soba
- narutomaki
- shiso \(plant\) (紫蘇)
- gunkanmaki
- wasabi
- tako-san wiener
- miso soup
- shumai \(food\)
- meandros (雷紋。ラーメンのどんぶりに描いてある四角い渦巻)
- fruit (フルーツ)
- banana
- cherry
- watermelon (スイカ)
- strawberry (苺)
- apple
- peach
- blueberry
- raspberry (ラズベリー)
- kiwi \(fruit\)
- dish (皿、食器)
- paper bag, grocery bag (紙袋)
- table
- basket
- tray (お盆)
- serving dome (クロッシュ、お盆にかぶせる半円形の蓋)
- tiered tray (スイーツを縦に重ねるやつ)
- tea pot
- teacup
- saucer (ソーサー)
- plate (皿)
- mamezara (豆皿)
- sushi geta (寿司下駄)
- tongs (トング)
- skewer (串)
- chopsticks (箸)
- yunomi (湯呑)
- mug
- beer mug (ビールジョッキ)
- coffee mug
- spoon (スプーン)
- wooden spoon
- fork (フォーク)
- bowl (ボウル)
- wooden bowl
- frying pan (フライパン)
- bamboo steamer (蒸し器)
- basket (バスケット)
そのほか
- pop background
映す範囲
構図や映す範囲は以下の要素で決まる。
- プロンプト
- アスペクト比
- シード
アスペクト比は重要だ。人物は縦長の方が良い結果が得られやすい。船は横長の方が上手く描ける。
身体を重視する場合は full body や tachi-e か breasts, navel, thighhighs, などの語をすべて入れる。靴を指定するのも有効。
- dutch angle (斜め)
- sideways (横長のアスペクト比の場合に着けると絵が崩壊しにくい)
- close-up
- pantyshot
- cowboy shot (頭部から中大腿部)
cowboy をネガティブに入れないとカウボーイが出てくる - landscape (横撮り)
- portrait (縦撮り)
- upside-down (さかさま)
- negative space (ネガティブスペース)
- cellphone photo (スマホ差分 スマホ越し)
- pov hands, cellphone photo。ネガに selfie や taking picture
アングル
landing のように地面を指定するとアイレベルが下がり、絵に変化が生まれる。
- from above (上)
- looking up
- top view (上)
- from below (下)
- looking up from below (見上げる)
- from side (横)
- from back (後姿)
- facing back (後ろ姿)
- orthogonal view (真正面)
- landing
正面
- straight-on (正面)
- selfie
- leaning against glass, hand on glass (ガラス越し)
防犯カメラ
- peephole
- fisheye
- backlighting
- vignetting (周辺減光。機能しないモデルの方が多い)
- looking away
引き・俯瞰・全身
- close-up (顔)
- portrait (鎖骨あたりまで。胸や脇を含まない)
- upper body (へそあたりまで)
- cowboy shot (膝上まで)
- feet out of frame (足をふくまない)
- full body (全身)
- tachi-e (全身)
俯瞰
- aerial
- aerial perspective
- satellite view
- panorama
- giant (巨人)
- giantess (巨大娘)
- from far away
- foreshortening (広角レンズで寄ることでパースが強調された絵。 fisheye もよく使われる。アップ・寄り)
- perspective
- dynamic pose, foreshortening, perspective, from above,
ライブ
- idol
- looks fun singing on stage surrounded by crowd
- spot light, penlight
- action scene
- idol singing pose
よくわからない場所
- beautiful landscape
- against backlight at dusk
- in the alice in wonderland
- luminous particles
- ☢(ポストアポカリプス)
- burning inferno
- lightning effect
- dusk twilight light particles embers
- sparkle background
- lightning
人物なし
- no humans
- nobody
- scenery
部屋
- bed, pillow, in the private room, covered by a blanket
- punishment room
- mattress (マットレス)
- bed
- hospital bed (病院のベッド)
汚部屋
- messy room
- many garbage bags
- trash
- stains on wall
- garbage dump
人
人は指定できる要素が多い。映す範囲、髪型、髪の長さ、色、肌の色、目の色、口の開け具合、ポーズ、表情、服、服の柄、年齢など。
highly detailed symmetric faces や extremely detailed symmetric faces、very gorgeous face は定番。だが顔をトリミングして、img2img で顔だけ再生成したものを後からペイントソフトで合成する方が高品質だ。
目を強調したい場合は "symmetric highly detailed eyes, fantastic eyes, intricate eyes" を追加する。
棒立ちになる場合は contrapposto を入れる。
人数
複数人出すと肌が融合しがちなので、長袖やスラックスを着せると融合しにくくなる。solo は solo focus に影響を受けて複数人描いてしまうことがある。
- solo
- 2girls, 3girls
- fff threesome (女3人)
- everyone (集合絵)
- absolutely everyone (大人数の集合絵)
- snuggled (分身? が量産される)
- snuggled up selfie (くっついて自撮り;百合っぽい何かを作りたいときに)
- crowd (背景が群集)
- onlookers (観客)
性別
1girl や 1boy は1人描かれるとは限らない。画面に男女2人がいる場合の画像のタグは、1girl, 1boy になるので。一人を描きたい場合は solo を指定する。
- 1girl
- 1boy
- genderswap (性転換)
- genderswap \(mtf\) (女体化)
- genderswap \(ftm\) (男体化)
kawaii
- kawaii
- bishoujo
- mesugaki
- succubus (サキュバス)
- demon girl (デーモン)
- adorable girl, adorable face
ロリ
Danbooru の loli タグは閲覧が有料なので、代わりに flat chest を使う。
- shortstack (ガキ巨乳)
- oppai loli (ロリ巨乳)
- toddlercon
- flat chest
- petite
- child
- chibi (chibi inset をネガにいれると、横に追加でチビキャラが描かれるのを防げる)
褐色
- tanned
- red skin
- brown skin
- suntanned red skin
- tanlines (日焼け後)
- bikini tan (ビキニ焼け)
- dark skin
- dark-skinned female
- 🧟♀(ゾンビ)
- pale skin (色白・死体)
ロボ
- cyborg girl
- robot girl
擬人化
- personification (擬人化)
- furrification (獣人化、ケモ化)
- monster girl (モンスター娘、亜人)
等身
- tall female (高身長・アスペクト比を縦長にすると出しやすい)
- chibi (SD キャラが生成されやすくなる)
- chibi inset (メインキャラの横に描かれているチビキャラ)
- nendoroid (ねんどろいどっぽくなる)
- dwarf
- ロリ
- shortstack
- toddlercon
- petit
年齢
- aged down (ロリ化)
- teenage
- gyaru (ギャル)
- mature female (成人女性)
- mature face (お姉さんっぽい顔)
- adult woman
- madame (マダム)
- milf
- elderly (初老)
- old woman (老女)
- old lady
表情
表情・目の形のプロンプト(呪文)一覧【Stable Diffusion】
画像AIの表情プロンプト集(効果ありのみ、画像あり著作権フリー)
無表情はネガティブプロンプトに troubled eyebrows, blush, smile を入れると作りやすい。
プロンプトに「confused, smile, crying, angry, multiple views」とすると、表情カタログが出力される。
- smile (目を開けてほほえむ)
- laughing (目を閉じて大口を開ける)
- :D
- 目を閉じて笑う
- closed eyes, ^_^
- closed eyes :D
- にらむ・ジト目
- glaring
- staring
- blank stare (にらむ・ジト目・ハイライトなし)
- expressionless, bored, half-closed eyes, light frown
- メスガキ
- mesugaki smile
- grin
- giggle
- evil grin
- tempting mesugaki smile with blush cheeks (挑発的な表情)
- seductive smile
- オスガキ
- 1boy, buzz cut, faceless male
- ドヤ顔
- smug
- smirk
- doyagao
- showing ahegao, mesugaki smile, torogao with frown eyebrows, excited (ドヤ顔)
- はにかみ
- embarrassed smile
- shy girl (垂れ眉・困り顔・頬染め)
- confused
- nervous
- nervous smile, uneven eyes, wavy mouth
- 驚き
- surprised
- constricted pupils (瞳孔の収縮)
- bulging eyes
- wide-eyed (瞠目)
- 元気
- sleepy, displeasing をネガる
- frown, puff of air, snort, v-shaped eyebrows (ふんす)
- scared (恐怖・怖がった・怯え)
- sulking (拗ねる)
- angry
- angry, grin, smile (やる気が出た)
- annoyed
- frown (しかめっ面)
- rolling eyes, looking up (しかめっ面)
- gloating (満足そうな)
- excited
- happy (困り眉を打ち消すのにも使える)
- dark persona (闇堕ち)
- pout (ふくれっ面)
- seductive face, nervous smile
- sadly closing her eyes and screaming
- :o, head tilt (キョトン)
- afterglow (放心)
- nervous sweating (冷や汗)
- v-shaped eyebrows
- furrowed brow (眉間にしわをよせる)
- head down (下向き)
- face down (下向き。枕に顔をうずめるときによく使う)
メイク
lips を入れると画風が変化するので、それを嫌う場合はネガティブに 3d を入れる。
- makeup (化粧)
- shading eyes
- eyeshadow
- plump lips
- lipstick
感情
- shaded face
- crying
- sobbing
- angry
- annoyed (マイルドな angry)
- sulking (拗ねる)
- bitter
- disgust (嫌悪・嫌な顔)
- embarrassed
- evil smile
- scared
- horrified
- lonely
- sad
- surprised
口
- closed mouth
- open mouth
- mole under mouth (口の下のほくろ)
- chestnut mouth, triangle mouth (三角形の口)
- ahegao (口を開ける)
- smirk (薄ら笑い)
- clenched teeth (歯を食いしばる)
- sharp teeth (ギザ歯)
- chestnut mouth (栗みたいな口)
- sharp teeth fang (牙)
- :d (:D)
- xd (XD)
- :>
- :3(猫みたいな口 ω。webui では :3 が強調と解釈されてしまうので、(:3:1.0) とすると安定する)
- :q (テヘペロ舌上向き)
- :p (テヘペロ舌下向き)
- :t (不機嫌)
- :i (ふくれっ面)
- :|
- :/
- :o
- :<
- tongue out (舌を出す)
- long tongue
- lips (Novel AI に入れると画風が大きく変わる)
食べる
eat が効かない場合は吐き出させる(vomit, spitting)。
- eat
- vomit
- blowing ramen out of her mouth
- spitting
- biting
- slurp (麺をすする)
- hold in her mouth
- mouth with 🚬 (タバコ)
頬
- blush (赤面)
耳
- pointy ears (エルフ耳)
鼻
dot nose
目
- bags under eyes (目の下のクマ・隈。ネガティブに bag)
- dot pupils (点目)
- constricted pupils (点目)
- trouble eyebrows (困り眉)
- beetle brow (太眉)
- long eyelashes (長いまつ毛)
- closed eyes
- half-closed eyes
- uneven eyes (左右非対称)
- jitome (ジト目)
expressionless eyesの方が近いかもしれない - tsurime (ツリ目)
- tareme (タレ目)
- glaring (睨み)
- upturned eyes (上目づかい)
- rolling eyes (目をまわす。上目づかい?)
- wide-eyed (瞠目)
- heart-shaped pupils
- heterochromia (色違いの目)
- jewelry eyes, jewel like eyes (キラキラした目)
- mind control eyes
- empty eyes
- sanpaku (三白眼)
- expressionless eyes
- hollow eyes
- slit pupils (猫目)
- cat👁️🗨️(猫目)
- @_@(ぐるぐる)
- | |(縦長の目)
- 0 0(縦長の丸目)
- > <
- = =
- ^ ^
- ^o^
- blindfold
(ニーアオートマタの YoRHa に影響を受けるので、yorha no. 2 type b, yorha no. 9 type s あたりをネガティブにれる)
ハイライトを消す
- empty eyes
- after rape, blank stare
眼鏡
- glasses
- semi-rimless eyewear
- rimless eyewear
- under-rim eyewear
- over-rim eyewear
- eyewear on head
髪
NovelAIで女性の髪形の呪文(コマンド)がわからないのでお団子ヘアーなど片っ端から検証してみた
- forehead (でこ出し)
- parted bangs (センター分け)
- hair pulled back (耳だし)
- blunt bangs (ぱっつん前髪)
- hair intakes (前髪の上の方にある三角のやつ)
- bob cut (ボブ)
- flipped hair (外ハネ)
- bedhead (寝ぐせ)
- fluffy (もふもふ)
- fluffy perm (ゆるふわ愛されヘア)
- sidelocks (もみ上げ、サイドロック)
- single sidelock
- short hair with long locks
- ahoge
- long hair
- absurdly long hair
- wavy hair
- curly hair (巻き毛)
- shiny hair
- hair flaps (頭の側面から生えている房状の毛)
- floating hair
- drill hair
- spiked hair (クラウドや遊戯王みたいな髪)
- messy hair (くせ毛・ぼさぼさ)
- hair spread out
- short hair with long locks (ショートヘアーに長いもみあげ。結月ゆかりみたいなやつ)
- hair rings (髪を結んで輪を作ってるやつ)
- tentacle hair (スプラトゥーン)
- hair behind ear (耳出し)
- big hair (ボリュームのある髪)
- low-tied long hair
- twintails
- low twintails
- low ponytail
- soviet ushanka hat
- 三つ編み
- braid (三つ編み)
- french braid (頭頂部から始まる三つ編み)
- single braid
- twin braids
- おだんご
- hair bun (おだんご)
- single hair bun
- cone hair bun (三角形のおだんご)
- double bun
- 目
- eyes visible through hair
- hair between eyes
- eyebrows hidden by hair (眉隠し)
- hair over one eye (片目隠れ)
- hair over eyes (両目隠れ)
マルチカラー
- colored tips (毛先だけ色変え)
- colored inner hair (ヘアインナーカラー)
- split-color hair (二色髪)
- two-tone hair (二色髪)
- streaked hair (メッシュ)
- gradient hair (グラデ)
- multicolored hair
- iridescent hair (玉虫色の髪)
アクセサリー
- tiara
- hair scrunchie (シュシュ)
- x hair ornament
- maid headdress
- hair ornament (髪飾り)
- hair clip
- hair tubes
- hair bobbles (ヘアゴム)
- hair ribbon
- hair bow (リボン)
- choker
解像度
服や顔の前に解像度ワードを入れると複雑なテクスチャになる。highly detaiiled face や extremely detailed lace、insanely detailed frills など。
- highres
- absurdres
- detailed
服
NovelAIでの衣装呪文一覧カタログ、全身女性立ち絵呪文と絵文字立ち絵構文のカタログ
服についての検証は A test of seeds, clothing, and clothing modifications が詳しい。ネックラインや帽子の種類を指定してもほとんど無視される。おそらく学習用画像のタグを付ける人が服飾に詳しくないからだろう。
上下セット
- maid
- wa maid
- office lady (OL)
- office lady, pencil skirt, id card, sleeveless collared shirt, pantyhose, bare shoulders
- office lady, pencil skirt, id card, collared shirt, suit jacket,
- office lady, pencil skirt, id card, white cardigan, black under shirt, shirt tucked in, pantyhose
- office lady, pencil skirt, id card, shirt, ribbed shirt, short sleeves, pantyhose
- skirt suit (リクスー)
- name tag
- nurse (ナース)
- police uniform (警察)
- loungewear (部屋着)
- pajamas (パジャマ)
- jumpsuit (つなぎ、作業着、ジャンプスーツ)
- tunic (チュニック)
- japanese clothes (和服)
- kimono (着物)
- ninja (忍者・くノ一)
ninja costume, ninja uniform - dress (ワンピース。one piece は漫画のワンピースになる)
- pinafore dress (ピナフォア、ジャンパースカート。袖なし襟なしドレス)
- sundress (袖なし襟なし肩だしドレス)
- microdress (ミニワンピ)
- gown (丈の長い女性用ドレス)
- princess (プリンセス)
- evening gown (イブニング・ガウン◆裾の長い、絹やサテンなどの豪華な生地で作られる、女性の正礼装(formal wear))
- cocktail dress (◆カクテル・パーティーや準公式な行事に着る準礼装。イブニング・ガウンほどは堅苦しくないドレスで、丈の長さは膝上からくるぶしまでとまちまち)
- ancient egyptian clothes (エジプト)
- american flag dress (アメリカ国旗)
- jiangshi (キョンシー)
- hanfu (漢服)
- miko (巫女)
- white kimono and red hakama (巫女)
- white yukata, hakama skirt (巫女)
- nun (修道女)
- habit (修道服)
- acolyte (ラグナロクオンラインの修道女)
- tabard
- naked tabard
- olympic スポーツ名 competition (lacrosse, wrestling, rhythmic gymnastics など)
- bike shorts (サイクルウェア)
自転車が邪魔なときは spandex shorts - fantasy priest
- bodystocking (全身タイツ)
- romper (ロンパース)
- bikini armor (ビキニアーマー)
- metal armor, cleavage, navel, thighs
- solo 1girl wears shiny metal armor kneeling spread legs in the dungeon, cleavage, navel, thighs, hair ornament, tiara, arms behind back, angry, blush, sweat
- ethnic costume-like bikini armor
- playboy bunny (バニー)
- long sleeves, detached collar, breasts out, navel, no panties, pasties, maebari, reverse bunnysuit, show off stomach (逆バニー)
- witch (魔女)
- witch, frilled dress, long dress, long sleeves, witch hat
- military uniform (軍服)
- suit (スーツ)
- china dress (チャイナドレス)
- china cheongsam
- jersey (ジャージ)
- track suit
- knightess (レディースの鎧)
- overalls (オーバーオール)
- blue dungarees (オーバーオール)
- overall shorts (ショートオーバーオール)
- naked overalls (裸オーバーオール)
- naked overalls shorts
- sarong (パレオ)
- loincloth (腰布)
- fundoshi (ふんどし)
- pelvic curtain (前垂れ)
- yukata (浴衣)
- mecha pilot suit (パイロットスーツ)
- pinafore dress (ジャンパースカート)
- travel attendant (客室乗務員)
- flight attendant (客室乗務員)
- waitress (ウェイトレス)
- dirndl (ディアンドル、村娘、メイド服のようなもの)
1girl with low twintails wear dirndl holding a basket of breads in the medieval village - idle costume (アイドル衣装)
- halloween costume (ハロウィン仮装)
- leotard
- sailor collar leotard
- collared leotard
- leotard wedding dress
- dirndl leotard
- cheongsam leotard
- long sleeves leotard
- bikini leotard
- highleg leotard, low leg denim shorts
- 学校
- serafuku (セーラー服。画像数 266k)
- bikini serafuku
- school uniform
- summer uniform (夏服)
- cheerleader (チアリーダー。ポンポンがついてくる。Prompt Editing で [cheerleader:0.2] 等とするとポンポンを消しやすい)
- cheerleader clothes
- leg up, miniskirt, cropped shirt, crop top, bare shoulders
- gym uniform (体操着)
- waring white collard shirt and slacks
- gakuran (学ラン)
- wedding
- wedding dress
- wedding veil
- leotard wedding dress
- 水着
- wrapped a large white towel
- rash guard (ラッシュガード)
- swimsuit
- slingshot swimsuit
- old-fashioned swimsuit
- school swimsuit
- one-piece swimsuit
- competition swimsuit
- slingshot swimsuit
- dress swimsuit
- frilled swimsuit
- bikini
- maid bikini
- o-ring bikini
- sling bikini top
- strapless bikini
- side-tie bikini bottom
- string bikini
- front-tie bikini top
- micro bikini
- untied bikini (ほどけ)
- striped bikini
- lowleg bikini
- slingshot swimsuit
- halterneck (ホルターネック 首に掛けるタイプ)
- criss-cross halter (前でクロスする首掛けタイプ)
- nipple cutout bikini (乳首穴ビキニ)
- pussy floss (ショーツを上に引っ張る。danbooru タグなら panty lift か bikini bottom lift)

highleg bikini bottom lift, sling bikini top
ass visible through thigh, legs apart, head tilt - tankini (上が tanktop もしくは crop top、下が bikini)
- 男
- jammers (膝上丈)
- legskin (脚全体)
- swim briefs (競パン)
- swim trunks
- fundoshi
装飾
- jewelry and accessories
- tiara (ティアラ)
- circlet (サークレット)
- crown (王冠)
- diadem (冠)
- head chain
- headpiece
- verteical strips (縦縞)
- horizontal strips (横縞)
- forehead protector (額宛て)
- cloak (マント)
- center frills (前立ての部分にフリルがついたやつ)
- epaulettes (軍服の肩についてるひらひら)
- pleated skirt
- high-low skirt (前が短くて後ろが長いスカート)
- victorian
- frilled
- embroidered (刺繍付き)
- filigree (金線細工)
- latex, wet, oily, metalic, shiny, luster (光沢のついた)
- latex rubber
- shiny slik (光沢のあるシルク)
- sash (帯・腰に巻いた布)
- backless (背中に穴の開いた服)
- spaghetti strap (細い肩紐)
その他の服
- パツパツの服
- undersized clothes
- taut clothes
- tented shirt
- button gap
- satin panties, satin bra (サテン。光沢のある布)
- crotch seam (ショーツの縫い目)
- collared shirt (ワイシャツ)
- dress shirt (ワイシャツ)
- hem (裾)
- baggy (ぶかぶかの)
baggy clothes, baggy pants - hoodie (パーカー)
- hood up (フードをかぶっている)
- hood down (フードをかぶってない)
- open hoodie (前開け)
- cropped hoodie (丈の短い)
- sleeveless hoodie (袖なし)
- shark hood (サメ)
- bow (ネックリボン)
- ribbon (Danbooru では ribbon は髪を結ぶものに限定して使う。ribbon は bow に比べて帯が細い)
- neck ribbon (ひも状のネクタイ。ボウタイ)
- naked ribbon
- ascot (首で結んだスカーフ)
- plaid bow (格子縞)
- bow bra (リボン付きブラ)
- bow panties (リボン付きパンティ)
- tail bow (しっぽリボン)
- dress bow (リボン付きドレス)
- camisole (キャミソール)
- crop top (へその見える丈の短いキャミソール)
- tank top (タンクトップ)
- chemise (シュミーズ。ウェスト下あたりまであるキャミソール)
- off shoulder (肩出し)
- strap slip (肩ひもずらし)
- pants (ズボン)
- dolphin shorts (短いズボン。ドルフィンパンツ)
- collared (襟付きの服)
- collared shirt (ワイシャツ)
- dress shirt (ワイシャツ)
- blazer (ブレザー)
- cardigan (カーディガン)
- midriff (へそ出し)
- impossible clothes (乳袋)
- impossible underware (張り付きパンツ)
- pantylines (パンティーライン)
- bralines (浮きブラ)
- knit cardigan
- shirt tucked in
- sheer mesh tops
- button gap (パツパツのシャツ)
- innertube, lifebuoy (浮き輪)
- oversized clothes
- jirai kei (地雷系)
- navel (へそ):"服飾指定, navel" でへそ出しになることがある。例:"navel, black sleeveless shirt, bare arms, bare shoulder"
- パンチラ
- pantyshot (しゃがみパンチラ、アクシデントによるもの)
- panty peek (ズボンの上にはみ出したパンティの上部)
- flash panty
- skirt, wind, panties (風パンチラ)
- lifting their own skirt
- shirttail (スカートを持ち上げた時のシャツの裾)
- shirttail, shirt, skirt lift, ass visible through thigh, highly detailed panties,
- white panties under black pantyhose, untucked shirt (スカートなし。skirt をネガ)
- gold metallic Texture-like-skin (金粉)
- taut clothes (ピンと張った服)
- crinoline (裾広がりのスカート)
- glitter (ラメ)
レース
- lace trim lingerie
- lace-trimmed negligee
- lace-trimmed panties
- lace-trimmed bra
- lace-trimmed choker
- lace-trimmed dress
- lace-trimmed hairband
- lace-trimmed legwear
胸
- criss-cross halter (紐が胸の上でクロスしてる)
- cleavage cutout (胸の開いたドレス)
- cleavage cutout, underboob (下乳カット)
- center opening (胸の真中が開いている服。sideboob と組み合わせるとよい)
- center opening, sideboob, corset, areola slip, skindentation
- no bra (他の服(オーバーオールとか)と合わせて使う)
- bralines (浮きブラ)
- off shoulders turtleneck sweater
脚
- denim panties
- denim shorts
- thigh gap (絶対領域)
- highleg (ハイレグ)
- highleg leotard
- highleg panties
- highleg swimsuit
- highleg bikini
- highleg dress
- pantyhose (ストッキング)
- fishnet pantyhose
- thighband pantyhose (ランガード)
- gusset (マチ)
- fine fabric emphasis (膝やももなどのストッキングが薄くなっている部分)
- シーム
- back-seamed
- crotch seam
- front-seamed
- side-seamed
- 柄
- argyle (アーガイル)
- polka dot (水玉)
- mismatched
- striped
- vertical stripes
- garter straps
- garter belt (ガーターベルト)
- thigh strap
- barefoot (裸足)
- skindentation (服による肌の食い込み。ニーソックス等を穿いたときにできる膨らみ)
- deep skin (指のくいこみ)
- trefoil (尻のくいこみ)
- shoe soles (靴の裏)
腕・肩
- bare shoulder (肩出し)
- strap slip (肩ひもずらし)
- strap pull
- sleeveless (ノースリーブ)
- detached sleeves (アームカバー)
- long sleeves (長袖)
- sleeves past wrists (萌え袖)
- sleeves past fingers (萌え袖)
靴
- high heels
- high heel boots
- high heel slides
- high heel sandals
- high heel sneakers
- block heels
- Christian Louboutin
- d'orsay heels
- kitten heels
- low block heels
- platform heels
- pumps
- stiletto heels
- strappy heels
- trapeze heels
- wedge heels
透過
AUTOMATIC1111の Prompt Editing で [cloth:nude:0.5] 等とする方法や、服を着た画像を img2img に入力して、nude 等のプロンプトで作成する方法がある。
- translucent (半透明)
- transparent (透明)
- see-through
- sweaty clothes
- covered by thin translucent cloth
- clear acrylic resin glass figma-like 衣服名
- transparent clear PVC full bodysuit
体形
太っている順に obese > fat > plump > curvy。
- muscular (マッチョ)
- abs (割れた腹筋)
- linea alba (控えめな腹筋)
- toned female (マッチョではない筋肉質な女性)
- muscular, skinny (痩せマッチョ)
- obese (肥満化)
- curvy (むちむち)
- plump (ぽっちゃりした)
- fat (肥満)
- obese
- thick thighs (太い脚)
- wide hips (でか尻)
- fat ass (でか尻)
- thicc, flat chest (貧乳でか尻)
- skinny (やせた)
- slender
- ribs (肋骨)
- narrow waist (細い腰)
- slim legs
- pregnant (妊婦。古いモデルではへそが乳首に変化しがち)
- stomach bulge
活動
- standing
- balancing
- water
- wading (水遊び)
- swimming
- bathing
- wading (水遊び)
- skinny dipping (全裸? 水浴び)
looking away, contrapposto, tilted head, completely naked 1girl skinny dipping in the lake - diving
- splashing (水しぶき)
splashing in the pool - squirting liquid (水遊び)
2girls squirting liquid in the pool - underwater
- running
- jogging
- fleeing
- chasing
- stretching
- cheering (応援)
- bubble blowing (シャボン玉やガム風船)
- biting
- hug
- boxing
- heavy breathing, panting (息切れ)
- dishwashing (皿洗い)
- sweeping (掃除)
- carrying
1girl carrying a girl - climbing (クライミング)
- cooking
- baking
- chocolate making
- roasting a meat
- stirring the curry
- covering (センシティブな部分を隠す)
- crawling (匍匐前進)
crawling in the pool はうまくいかない - cutting a meat
- dancing
- pole dancing
- dodging
- dressing
- drinking
- drunken at the bar
- dripping
- driving
- drooling (よだれ)
- drying
- dual wielding (二刀流)
- eating
- chewing (噛む)
- swallowing (飲み込む)
- tasting
- feeding (餌付け)
- pov feeding
- fainting (失神)
- falling
- fidgeting (もじもじ)
- fighting
- firing (発泡)
- flailing (腕を振る)
- floating (浮かぶ)
- flying (飛行)
- gardening (庭いじり)
- watering (水まき)
- glowing (発光)
- grabbing
- hairdressing
- brushing hair
- hair tucking (髪をかきあげる)
- hanging (吊るす)
- hatching (孵化)
- healing
- hiding (隠れる)
- hitting
- holding
- jumping
- hopping
- pounching (飛び込む)
- kicking
- kissing
- kneeling (膝をつく)
- knocking (ノックする。ドアから覗いている構図になりやすい)
- launching a rocket
- leaning against a car (車によりかかる)
- licking
- lifting
- weightlifting
1girl weightlifting, squatting spread legs - leg lift (leg lift は大股開き。leg up は脚を少し上げている状態も含む)
- leg up
- standing split (I字)
- looking
- looking at viewer
- facing to the side
- looking at object
- looking away
- looking back
- facing away (後ろ姿)
- looking down
- looking up
- profile (横顔)
- straight-on, profile, looking at viewer, looking to the side (横顔目線はこちら)
- lying
- lying on back (逆さ寝)
- measuring
- melting
melting chibi - moaning (呻吟)
- nose picking (鼻ほじり)
- opening
- peeking (のぞき)
- peeking out
- blurry foreground, peeking, pov doorway
- petting
- pitching (投げる)
- playing
- playing a piano
- playing a guitar
- playing games
- playing nintendo
- playing soccer
- pointing (指さし ヨシ!)
- poking (つく)
- polish (磨く)
- pouring (注ぐ)
pouring water into a cup of glass from a pitcher - praying (祈祷)
- programming (プログラミング)
- protecting
2girls protecting - pulling
- punching
- pushing
- rappelling (ラぺリング・懸垂下降)
- reaching (手を伸ばす)
- reaching towards viewer (前に手を伸ばす)
- reading
- reloading (再装填)
- repairing (修理)
- resting
- riding
- broom riding (箒で飛ぶ)
- umbrella riding (傘で飛ぶ)
- piggyback (おんぶ)
- roaring (咆哮)
- rolling (ローリング)
- running
- screaming (叫ぶ)
- searching
searching a book in the library - sharing
- shaving
- shopping
- shouting (叫ぶ)
- singing (歌う)
- sinking (沈む)
- sitting (座る)
- reclining (リクライニング)
- sketching
- skipping (スキップ)
- slashing (刀で切る)
- sleeping (寝る)
- sliding (スライディング)
- slipping (滑る)
slipping on the ice floor - smelling
- smoking
- sneezing (くしゃみ)
- snowing
- spanking (尻たたき)
- spitting
- spraying
- squeezing
squeezing breasts - stacking
- standing
- staring
- stepping
- stomping
- strangling (絞殺)
- struggling (抵抗)
- studying
- sucking
- breasts sucking
- self breast sucking
- finger sucking
- thumb sucking
- toe sucking
- sulking (拗ねる)
- summoning (召喚)
summoning a tentacle - sunbathing (日焼け)
- surfing
- broom surfing (箒の立ち乗り)
- sky surfing
- swinging (揺れる)
- tail fondling (しっぽいじり)
- talking
- teaching
- text messaging (コマが割られたり、吹き出しが出たり、LINE になる)
- thinking
- throwing
- touching
- training
- trembling (震えエフェクト)
- trolling (怪物が出てくる)
- twitching (痙攣)
- tying (ひもなどを結ぶ)
- tying footwear
- typing
- unzipping
- vomiting (吐き出す)
- waiting
- walking
- pet walking (ペットと散歩)
- wallwalking
- washing
- body soaping
- watching
- whisking (かき混ぜる)
whisking in a bowl - whispering (ささやき, hand on own mouth)
- whispering in ear
- whistling
- working
- wringing (絞る)
ポーズ
ポーズを固定したい場合は、ControlNet を使う。
- contrapposto (コントラポスト、モデル立ち)
- v (ピース)
- double v (ダブルピース)
- ojou-sama pose (お嬢様ポーズ)
- clenched hand (握りこぶし)
- handshake (恋人つなぎ?)
- dynamic pose
- stylish pose
- dodging
- beckoning (手招き)
- open arms for viewer (手を前に突き出す)
- down one knee (片膝立ち)
- pigeon-toed (内股、内また)
- indian style (胡坐)
- butterfly sitting (胡坐)
- sitting on (~の上に座る)
- kneeling (膝立ち)
- tilting head (首をかしげる)
- stroking own chin (自分のあごに手を当てる)
- leaning to the side (なにかにもたれかかる)
- dakimakura of (ベッドの上で寝た画像になる)
dakimakura of ~ from back (後姿)
dakimakura of ~ looking back (後姿で振り向き)
dakimakura medium from behind - spooning (側位)
- lying on back (仰向け)
- lying on side (side by side をネガ)
- lying on lap (膝枕)
- knees together feet apart
- arms up
- bent over
- flirt (いちゃつく)
- breast rest (何かに胸を乗せている)
- breasts on table
- finger to mouth
- finger to cheek
- spread arm (横に手を広げる)
- outstretched arms (手を広げる・突き出す)
- zombie pose
- against wall (壁伝い)
- elbow rest (テーブルに肘をつく)
- 背中
- back
- back focus
- median furrow (背中の中心線)
- 脚
- spread legs (脚大開き)
- (spread legs:0.5) down (マイルドな脚開き)
- dilation tape (テープくぱぁ)
- spread legs down
- wide spread legs
- crossed legs (脚組み)
- watson cross (立ったまま脚クロス)
- legs apart (立った状態で少し開いている)
- legs up (まんぐり返し)
- leg up (片足上げ)
- folded (まんぐり返し)
- hold up knee (膝抱え)
- m legs (M字開脚)
- sitting thighhighs (着座のふともも)
- のけぞり・エビぞり
- leaning back
- leaning back, squatting (腰の突き出し)
- sway back
- arched back (横からのアングル)
- armpit (脇)
- turning around (振り向き)
- looking back, from behind, looking at viewer (振り向き)
- looking back, from behind, looking at camera (振り向き)
- crossed arms (腕組み)
- hugging own legs (膝抱え)
- holding hands (手を握る)
- leg lift, leg up, standing on one leg, standing split (I字、片足立ち)
- head in the pool of water (水に頭までつかる)
- submerged up to shoulders in a pool (水に肩までつかる)
- partially underwater shot (カメラが一部水に浸かる)
- on one leg, arm up, looking up, ballet posing (バレエ)
- human stacking 尻タワー
百合キス
- hug
- embrace each other
- hug from behind
- hug each other tight
- symmetrical docking
- comforting each other (慰める)
- cuddling each other (愛撫。ベッドシーンになりやすい)
- handshake (恋人つなぎ?)
- kiss
- touch each other's lips face to face
- blowing kis (投げキス)
- implied kiss
- grabbing another's chin (あごクイ)
- incoming kiss (キス待ち)
kiss, closed eyes - imminent kiss (キス直前)
- multiple giris, kissing nose, yuri
- a girl kissing a girl
- french kiss (ディープキス)
- 2girls kiss
- after kiss
- 2girls, yuri, girl on top, lying on person, on back, on stomach (二人重ね)
エフェクト
- speech bubble (吹き出し)
ネガに english text, engrish text, chinese text, korean text を入れると日本語のテキストになりやすい(意味のある文章になるわけではない)。 - sound effects (オノマトペ・擬音・擬声)
- spoken object (吹き出しの中に絵があるもの)
- screaming (叫び声)
- puff of air (フンス・ため息)
- ?, ??
- !, !!
- ...
- +++(笑っているときにでるやつ)
- ^^^(気付き、衝撃エフェクト)
- notice lines (気づいた時の3本のしたじき)
- !?
- heart shape particle
- spoken heart
- spoken question mark
- spoken musical note
- motion lines (モーションライン・勢い線)
- speed lines
- jaggy lines (モーションブラー)
- emphasis lines (集中線)
- steam
- steaming body
- heavy breathing (息切れ)
- trembling (震えエフェクト)
- sepia
- autochrome
- lomography
- diffraction spikes (光条・回折スパイク)
椅子
- chair
- bench (屋外・だいたい木製)
- couch (ソファー)
- stool (背もたれのない椅子)
- exercise ball (バランスボール)
そのほか
銃は型番で指定すると品質が上がる。
- id card (学生証・身分証・社員証)
- name tag
- oil-paper umbrella (和傘)
- thick thighs (太い脚)
- sweaty skin (汗ばんだ)
- wet
- call of duty, aiming, guns (銃)
- smoking a cigarette holding in her mouth (咥えたばこ)
- wand (小さい杖)
- staff (長い杖)
- sushi, nigiri (寿司)
カメラ
カメラ系の語は Stable Diffusion や Waifu Diffusion v1.2 で効果がある。
カメラ、レンズ、シャッタースピード、絞り、ISO を指定するが、Waifu Diffusion では影響が小さい。
ボケをなくしたいときは blur や bokeh をネガティブプロンプトに入れる。sharp focus みたいな語をプロンプトに入れても意味がない。なぜならピントが合っている写真にいちいち sharp focus みたいなタグをつけないから。
- bloom
- bokeh
- soft focus
- film grain
- fisheye lens
- macro
- vintage
- lens flare
- sun flare
ライティング
シーンライティング
- twilight light
- volumetric lighting
- specular lighting
- cinematic lighting
オブジェクトライティング
- front lit (正面からの照明)
- soft lighting
- studio lighting
- beautiful lighting
- dynamic lighting
- dramatic lighting
- golden hour
- worm lighting
- cool lighting
- sun light
UI・動画配信風
- view finder
- recording
- youtube, virtual youtuber, livestream, chat log
作風
作風リスト
- official art に作品タグを組み合わせる方法がある
- list of artists for SD v1.4 A-I/J-Z
- SD Artist Collection
- Midjourney の画風調査
- 画風・エフェクト関係の呪文の一覧【Waifu Diffusion・NovelAI】
リアル
- realistic
- octane render
アウトライン
- outline
- line drawing
- comic art
- outlined vector graphics
- layout sketch of
- blueprint
線画
- monochrome, white background
- line drawing, no color, white background, clear black lines on white background, fine writing
線画なしフラットイラスト
- flat color, no lineart
- ネガに lineart
アニメ
- official art, anime coloring, anime screenshot ネガに real life, 3d, realistic, photorealistic
- anime coloring
- anime screenshot (アニメのスクショ)
- magazine scan
- megami magazine
- official art
- toon \(style\)
- retro artstyle
- 1980s \(style\)
- 1990s \(style\)
- 2000s \(style\)
ドローイングスタイル
sketch, graphite \(medium\) を入れると、手や細部の粗が目立たない。
- no lineart (主線なし)
- crosshatching
- detailed and intricate
- lineart
- sketch
- graphite \(medium\)
- colored pencil \(medium\)
イラスト
- pop-art
- muted color
- simple and muted color palette
- nihonga
- ukiyo-e
- sumi-e
- illustration of
- bishoujo figure (フィギュア風)
- wallpaper
- concept art
- comic book
- color pencil drawing
- pastel
pale color - watercolor \(medium\)
- watercolor pencil \(medium\)
- calligraphy brush \(medium\)
- oil painting \(medium\)
- one-hour drawing challenge, sketch
複数
reference sheet は横顔や斜め後ろ姿等を描いてくれるので、設定を作るときに便利。ただし服装や色が違ったりする。
- column lineup (枠で区切ったキャラ一覧)
- multiple views (設定画みたいに1画面に複数描かれている)
- sprite sheet
- collage (同じ画像が並ぶ)
- zoom layer (背景にキャラのズームをつかっている画像)
- projected inset
設定画
- reference sheet
- reference sheet of キャラ名
- reference sheet, turnaround, multiple views, full body
- reference sheet, same size face, concept art (頭だけいろんな方向から描いたもの)
- reference sheet, multiple views,same size face, expression chart
- expression chart, multiple expressions (表情リスト)
- chart
- bust chart (乳比べ)
- costume chart
- diagram
- relationship graph
- stats
特殊
- pixel art
- dot art
- 8-bit
- 16-bit
- isometric (キューブの中に部屋を配置した絵)
- isometric room
- trading card
- meme
- soviet poster
- movie poster
- voxel art
- screenshot
- anime screenshot
- fake screenshot
- fake phone screenshot
- game screenshot
- screenshot inset
- cover (表紙)
- magazine cover
- comic cover
- doujin cover, nsfw
- newtype cover
- adult comic cover
- on the cover of a manga
モノクロ
- monochrome rough sketch
- grayscale
- screentones
人名
- kyoto animation
- studio ghibli
- cygames
- krenz cushart
- ilya kuvshinov
- greg rutkowski
- utagawa kuniyoshi
- william adolphe bouguereau
- makoto shinkai
- tsutomu nihei (白黒になりがち)
- kanna hashimoto
- suzu hirose
- range murata
- akihiko yoshida
- makoto shinkai
- yoshitaka amano
- alphonse mucha
- william adolphe bouguereau
- liraphael lacoste (風景画に強い)
Map
- TRPG, map, concept sheet, fantasy, rampart, walled city
- square combat map, quarter view
- map, a part of the continent
- map of zoo park
- 3d map of cyberpunk city
- a floor plan of a house
- layout of a house
プロンプトガチャ
プロンプトを空にして、ネガティブプロンプトだけで生成すると普段見れないシチュエーションが出てくる。
ランダムなテキストを入力すると抽象画になる。
- 376458312764531678438
- dlakfjhoadiygkuwehbfahajugfoaef
- adfkjhgae6w3rhja367iregaiklfdga7346
AI が描いた絵の見分け方
AIが自動生成した画像かどうか見破って判別できると自称する複数のツールをテストした結果とは?)
無加工の場合は、手と拡大した目を見ればすぐにわかる。現在の画像生成 AI は画像を圧縮した状態で絵を描いているため、細部がつぶれる。なので、AI らしさをすべて修正するためには画像全体をレタッチする必要がある。
1. 細部が甘い
- 手が崩れている・指の本数がおかしい
- 服やアクセサリーの細かい装飾が崩れている
- ブラやショーツについているリボンが上手く描けない
- フリルやレースのディティールがつぶれている
- しわの量が過剰
- 毛先が不明瞭・毛先が溶けている
- 目のディティールが甘い
- 目の描き方が左右非対称
- ハイライトの形が崩れている・位置がおかしい
- 瞳孔が崩れている
- 耳の形がおかしい
- 歯の形がおかしい
- 脇だけが異常に書き込まれている
- 背景
- 水平垂直線がゆがんでいる
- 窓の間隔がおかしい
- 窓の細部がおかしい
- 文字がおかしい
- 路面標示がおかしい
- レンガの細部がおかしい
2. 背景の連続性がない
- 閉領域の背景がおかしい;閉領域とはたとえば、手を腰に当てた時にできる、腕と身体で作る空間のこと。髪のループでもよく閉領域は生成される。閉領域では背景の連続性が失われやすい。

閉領域の背景の色が薄い
- 水平線がずれている

水平線がずれている

水平線、閉領域ともにおかしい
3. png なのに jpeg ノイズがある
AI は jpeg ノイズを学習してしまっているので、png で保存された画像にも jpeg ノイズが乗る。ただし、jpeg 画像でコラージュされている場合は AI が生成したとは限らない。
AI が描いた絵の識別テスト
外部リンク
NSFW(職場閲覧注意)
単語集
nude と completely nude
danbooru タグの nude は胸と股間にだけ服がない状態。全裸は completely nude を使う。
deep pentration
deep penetration はペニスが見える状態。見えないぐらい深い挿入は「ass ripple, implied sex」で、sex, deep penetration, uncensored を使わない・ネガに入れる。
場所
- brothel (売春宿)
- prostitution (売春)
- stone floor
- stone wall
- dungeon
- cage
- partially submerged (一部水に浸かっている)
関係性
- assertive female (女性上位)
- femdom (BDSM での女性上位)
- onee-shota (おねショタ)
- onee-loli
- age difference
- size difference
- bisexual female (バイ女)
- ffm threesome, bisexual female, 1boy, 2girls, breast sucking, group sex (女女男)
大人数
- 6+boys
- gangbang
- crowd
- group sex
- surrounded by multiple guys
- in a mosh pit
- on a mosh pit, high angle view
- surrounded by crowd
- love train
- groping (おさわり)
- multiple girls, 6+girls, random hair, friends, everyone
性器など
- pussy (女性生殖器が見えているときに使う。アナルセックスにこのタグが付いていることも多い)
- vaginal (女性生殖器に何かが入っているときに使う)
- cameltoe (布越しのすじ)
- cleft of venus (割れ目)
- groin (鼠径部)
- groin tendon (鼠径部のすじ)
- pussy peek (大陰唇)
partially visible vulva - maternity (服を着ている)
- partially visible vulva (食い込み)
- futanari (ふたなり)
- futa with futa
- pov breasts ,futanari pov (ふたなり主観視点)
- futa with female (ふたなりレズ)
- 1boy, huge breasts, large penis (ふたなり。男に乳を盛る)
- penis growing out of his crotch
- pubic hair (陰毛)
- female pubic hair
- male pubic hair
- hip
- dimples of venus (ウェヌスのえくぼ。尻の割れ目の上にある2つの影)
- ass visible through thigh (前から見える尻)
- anus (肛門)
- anal (尻穴に何かが入っているときに使う)
- くぱぁ
- spread pussy
- dilation tape (テープくぱぁ)
- spread legs
- half-spread pussy
- spreading another's pussy
- crotch focus
ペニス
- foreskin small boy penis (包茎の小さいペニス)
- erection (勃起)
- multiple penises
- veiny penis (静脈)
- disembodied penis (宙に浮いているペニス)
- flaccid (勃起していないペニス)
- penis awe (見せ槍)
- twitching penis
- invisible penis
- penis outside (服や乳で隠されたペニス)
- fellatio (フェラチオ。咥える側が動く)
- reverse fellatio (頭を 90 縦に傾ける。顔が見えにくくなる)
- irrumatio (竿役が動く)
- deepthroat (ペニスを深く咥える)
- throat bulge (喉ボコ)
- glansjob (亀頭責め)
- cuphand
- covered penis (ズボンを穿いた状態での勃起ペニス)
- naked keeling open mouth 1girl licking faceless male's well drawn penis from side and giving handjob in the classroom. 1girl has black long hair, hime cut, black eyes, a fear of sad tears, petite big breasts, large nipples, white skin, red leather collar. trembling motion lines (フェラ)
触手
触手は髪と融合しがちなので splatoon, inkling, fused hair あたりをネガティブに入れる。
- tentacle pit
- tentacle grab
- surrounded tentacles swarm
- octopus, tentacles
- penis tentacle
- tentacles, tentacle sex
- tentacle-like thigh strap (触手が脚に巻き付く)
- tentacle wrap neck around
- suction cups (吸盤)
- surrounded by many tentacles swarm in dungeon, soaked with dripping mayonnaise
- stationary restraints (強制絶頂)
- tentacles covering eyes (触手目隠し)
表情
- ahegao
- ahegao, smile
- fucked silly (んほぉ)
- dashed eyes
- orgasm
- tearing up
- crying with eyes open, sad, tears
- mouth drool (よだれ)
- clenching teeth (歯ぎしり)
- furrowed brow
- heavy breathing (息切れ)
- runny makeup (涙で化粧・マスカラが落ちる)
- puckered lips (キスするときの唇・唇突き出し)
- rolling eyes, :o, mouth pursed, looking up (オホ顔)
- half-closed eyes, eyes rolling back, puckered lips, ahegao, drooling, trembling, sweat, ahegao, fucked silly, female orgasm
体位
This Is What Your Sex-Position Bucket List Should Look Like。
- pov vaginal sex (主観視点)
- crotch rub (自慰)
- pillow humping (枕オナニー)
- intercourse with a man
- reverse suspended congress (アナル固め・駅弁・抱えセックス)
- full nelson
- folded
- spooning (松葉崩し)
- on side, leg up, sitting on person, sitting on leg, leg grab ネガに spread legs, sex from behind
- tribadism (貝合わせ)
- cunnilingus (クンニ)
- cunnilingus, cum in pussy, yuri, 2girls (精液掃除)
- sitting on lap (膝の上でいちゃいちゃ)
- バック
- hug from behind (バック)
- girl on top, from behind, from above (バック)
- prone bone (寝バック)
- 騎乗位
- straddling(騎乗位)
1girl, from below, underboob, school uniform skirt, briefs, ceiling, straddling - girl on top, spread legs (騎乗位)
- cowgirl position (騎乗位)
- upright straddle (対面座位)
- squatting cowgirl position (スクワット騎乗位)
- reverse cowgirl position (背面騎乗位)
- humping (性器のこすりつけ)
- dry humping
- bulge press
- 2girls humping
- grinding (股コキ、素股)
- cooperative grinding
- 69
- cunnilingus
- doggystyle, all fours (四つん這い)
- from behind, looking at viewer, looking back, doggy style
- doggystyle
nsfw portrait photo \(medium\), official art, despair loli child lying, doggystyle vaginal pov sex from behind, cum in pussy, grabbing another's legs , speed lines - view straight on, sex, doggy style, all fours (四つん這い正面)
dog, animal ears をネガティブに入れる - reverse cowgirl position
- missionary (正常位)
- standing missionary (立ち正常位)
- spooning (側位)
- table sex (角オナ)
- full nelson (アナル固め)
- tribadism (貝合わせ)
- human stacking 尻タワー
- leg lock (だいしゅきホールド)
- leg lock, boy on top, from side, hand on another's head
ネガに face-to-face
ポーズ
- imminent vaginal (膣性交寸前)
- guided penetration (挿入補助)
- imminent penetration (挿入寸前)
- just the tip
- :>=(ひょっとこフェラ・バキュームフェラ)
- implied sex (結合描写なし)
- dry humping (レズパコ 交尾ごっこ)
- skirt lifted by self (スカートたくし上げ)
- lifted by another
- pov hands
- skirt lift
- skirt hold
- wind lift
- curtesy
- pov across bed, from ass, briefs (ベッドで尻向け)
- top-down bottom-up (ケツ上げ)
- looking through own legs
- breast press (おっぱい押し付け)
- clasp with hands (手ブラ)
- cupping hands (手で受ける)
- all fours (四つん這い)
- squatting, paw pose (ちんちん)
- wall, bend over backwards (壁尻)
bottomless 1girl bend over in the city road, from behind, nsfw - spread legs
- legs apart (立った状態で少し開いている)
- spread pussy
- showing pussy
- cervix
- pussy looking through (局部見せつけ)
- holding another's wrist
- v legs(両脚上げ)
- squatting and arms behind head (エロ蹲踞)
- spread legs, squatting, arms behind back (エロ蹲踞手後ろ)
- girl squatting spread legs widely like dog statue pose thighhighs (M字開脚)
- bowlegged pose, tiptoes, standing (蟹股・ガニ股)
- bowlegged pose, spread legs, standing, from behind
- sitting on potty (便座に座る)
- fellatio, pov
- 1boy sitting on sofa,1girl on side on thigh,fellatio,hand job
- eating a sausage
- licking a sausage
- a sausage is inserted into her mouth
- cameltoe (下着のマンスジ)
- sleep molestation (睡眠姦)
- unconscious, expressionless, pale skin, saliva, full body (死体。ネガティブに blush)
- pov male body
- jack-o' challenge
- reach-around (背後から手コキ)
バックの場合
stomach, navel, boob のような正面から見えるパーツをネガティブに入れる。
- back boob
脱衣
ネガティブに see-through, nipples を入れると服の上から乳首が描かれるのを軽減できる。
〇〇 lift は〇〇をネガティブに入れると2重描写を防げる。例えば camisole lift の場合は camisole をネガティブに入れる。panty pull も同様。例:naked, camisole lift, panty pull ネガティブ camisole, panties, panty。
- 脱ぎかけ。bare shoulders をネガに入れると前開けになる
- undressing
undress bra, nipples, navel - open clothes
- open shirt
- unbuttoned shirt
- center opening (胸の真中が開いている服。sideboob と組み合わせるとよい)
- center opening, sideboob, corset, areola slip, skindentation
- partially unbuttoned
- partially undressed (脱ぎかけ)
- white naked shirt
- bra visible through clothes (透けブラ)
- bralines (浮きブラ。bra visible through clothes が透けすぎる場合)
- changing clothes
- pulled by self
- bikin pull
- take off a 衣類名
- changing room
- bikini bottom aside
- clothed female nude male
- clothed sex
- ずらし
- clothes lift (たくし上げ)
- clothes pull (引っ張って服ずらし)
- clothing aside (服ずらし)
- lift
- lifted by another
- bra lift
- bikini top lift
- sweater lift
- shirt lift
- skirt lift
- dress lift
露出
- flasing
- oppai challenge
- one breast out (片乳出し)
- selfie
- public indecency (公然わいせつ)
- exhibitionism (露出症)
- public nudity (露出)
- pee (放尿)
- peeing self (おもらし)
- urinate, yellow urine pool out of pussy
- standing 1girl wear chinese clothes see-through China white cheongsam, pelvic curtain, no panties, no bra, indoors, confused smile, cameltoe
装飾
- nipple piercing
- nipple bar (バーベル型の乳首ピアス)
- nipless
- body writing (落書き)
- tally (体に描かれた正の字)
- wedding veil
- リード
- leash
- chain leash
- viewer holding leash
- 首
- choker (チョーカー)
- collar connected by a chain
- animal collar (動物用首輪)
- harness collar
- 拘束
- padlock (南京錠)
- pillory (拘束板)
- harness cuffs
- handcuffs
- shackles (手枷)
- spreader bar (手足を固定する棒)
- restrained
restrained to a bed, spread legs, arms up, collar - tattoo
- pubic tattoo (下腹部の淫紋)
- stomach tattoo
- barcode tattoo
服
ショーツの後ろにリボンがつく場合は、ネガに ribbon panties, bow panties。
- 全身
- cling wrap (サランランップ)
- nightgown
- lingerie
- negligee
- wrapped a large white towel
- naked towel, strapless onepiece
- see-through white bikini
- torn clothes (破れた服)
- torn clothes, nipples peek, nipple slip
- torn chainmail
- bondage rope bind (緊縛)
- belted (ベルトいっぱい)
- fish net
- panties(丈長のが欲しい場合は thong, lowleg, g-string をネガに入れる方法や、プロンプトエディティング [briefs:panties:0.2] を使う方法がある)
- crotch seam (縫い目)
- calvin klein (有名な下着ブランド)
- cotton panties (女児パンツが出やすい)
- [briefs:cotton panties:0.3] (丈長のショーツ)
- briefs (ブリーフ)
- highleg briefs
- boxer briefs
- side-tie panties
- panties aside (ショーツずらし)
- pulling own clothes (指でずらす)
- panties aside, pussy, hand on own crotch
- panties aside, adjusting panties
- pussy floss (ショーツを上に引っ張る。danbooru タグなら panty lift
- panty pull (脱ぎかけ)
pulling down panties - panty pull, no panties ネガティブに panties (二重パンツ問題対策)
- no panteis
- crotchless panties (股間部なし)
- no panties
nsfw cowboy shot, cleft of venus, 1girl wear no panties and camisole with covered nipples - pussy cutout
- pubic hair (陰毛)
- anus peek
- 胸
- bra peek (ブラチラ)
- towel over breasts
- nipple slip (乳首チラ)
- torn clothes, nipple slip
- areola slip (乳輪チラ)
- nipple cutout
- topless
- pantyhose
- torn pantyhose
- navel (へそ)
- open fly (ズボンの前ボタンやチャックを開けた状態)
- strap gap (紐と体の隙間)
- cloth aside
- strapless, naked towel (danbooru タグ)
- loincloth (腰布)
- fundoshi (ふんどし)
- pelvic curtain (前垂れ)
- diaper (おむつ、おしめ)
- boyshort panties (ボーイレッグ。dolphin shorts ドルフィンショーツも近い )
乳全般
サイズや形状については breasts を参照。
oppai も使える。
- breasts out (乳だけ出してる)
- no bra
- lactation (乳の分泌、授乳)
- nipples (乳首)
- covered nipples (浮き乳首、胸ポチ、透け乳首)
- colored nipples (変な色の乳首)
- puffy nipples
- perky breasts
- pointy breasts
- perky breasts, (sagging breasts:0.5)
- huge nipples (デカ乳首)
- large areolae (デカ乳輪)
- inverted nipples (陥没乳首)
- heart pasties (ハート形のニップレス・前張り)
- breast grab
- grabbing another's breasts
- deep skin (鷲掴み)
- kneading breasts, pov male hands (画面外から腕を突き出して胸をもむ)
- pov breast grab
- pov kneading breasts
- kneading breasts (乳こね)
- squeezing breasts
- grabbing from behind (後ろから乳をつかむ)
- hands on breasts, covering breasts (手ブラ)
- guided breast grab (乳を揉ませる)
- groping (おさわり)
- breast squish (e621)
- nipple pull
- nipple pull, stretched breasts, from side, unaligned breasts
- sideboob (横乳。正面の構図を出したくないときに使う)
- underboob (下乳)
- open at the chest
- breast bondage
- hanging breasts, leaning forward, hands on own knees (前かがみで胸を強調)
巨乳
- (huge breasts:1.5)
- huge bomb breasts
- cleavage of huge breasts
- large breasts
- huge breasts
- sagging breasts (垂れ乳)
普乳
- medium breasts
- small breasts
- neckline
- decollete
貧乳
貧乳は巨乳系の語をネガティブプロンプトに入れるのが確実だ。flat chest は有料の loli タグの代わりに使われていて、ロリ化する傾向にある。
大人の貧乳は tall female, mature female, skinny, narrow waist 等を併用して、ネガティブに child 等を入れる。
- flat chest
- small proportions
- skinny
- [[[[[breasts]]]]]
汗
- sweaty skin
精液
img2img を使うと好きな場所に精液を配置できる。
- pile of cum
- cum in pussy
- internal cumshot
- cumdrip (溢れ精液、ペニスなし)
- cum overflow (溢れ精液、ペニスあり)
- cum pool (床の精液)
- ejaculation
- female ejaculation (潮吹き)
- ejaculating while penetrated
- facial (顔射)
- bukkake
- cum string
- pussy juice trail
- projectile cum
- cum in mouth
- cum on body
- cum on tongue
- cum on breasts
- cum on stomach
- cum on ass
- cum on hair
- impregnation, fertilization, ovum (受精エフェクト)
- mayonnaise in bath in 1girl (精液風呂)
- cum bath filled with mayonnaise (精液風呂)
- take a cum bath (精液風呂)
- マヨネーズ(SFW なモデルで使う)
- mayonnaise
- slimy skin
- shiny
- shiny skin
- covered in white gooey paint
- wet with opaque globs of mayonnaise
- opaque sticky white goo
- dripping with strands of white goo
- ((((white slime)))), (wet)
ゴム
- pointless condom (ゴムがあるのに中出し)
- condom (ゴムの箱)
- single condom
- used condom
- condom wrapper (未開封のゴムひとつ)
- condom packet strip
- multiple condoms
- holding condom
- condom on penis
- condom packet strip
- condom in mouth
事後
- after sex
- manga, 2koma, instant loss
- after vaginal
暴力
- punching
- punched
- stomach punch
- vomitting
- molestation (痴漢)
groping, fingering - bdsm
- bruise (打撲・あざ)
- injury (ケガ)
- punching
- ryona
- strangling (首絞め)
- asphyxiation (窒息)
- abuse (虐待・酷使)
- fingering (手マン)
- finger in pussy
- pain
- defloration (破瓜)
- blood on penis
- breast grab
- stomach bulge
- force-feeding
縛り
- bound (sfw, nsfw 両方)
- entangled (アクシデントで絡まった)
- tied up (sfw)
- restrained
- handcuffs (手錠)
- bondage (nsfw)
- bound arms
- bound wrists
- bound ankles
- bound legs
- ribbon bondage
- breast bondage
- arms behind back (後ろ手)
- arms up
- shibari over clothes (服の上から縛る)
- gag (猿轡)
- ball gag
- improvised gag (テープや布で口をふさぐ)
- bit gag (竈門禰󠄀豆子)
- tape gag
- cloth gag
- cleave gag (噛ませ猿轡)
- ring gag (口が開いているタイプ)
- gag removed
- cuffs-to-collar
- separated
- separated arms
- separated legs
- separated wrists
- shrimp tie (海老責め)
- skirt tied over head (茶巾縛り)
- strappado
- pillory (首枷・晒し台)
- box tie (手を後ろで縛る)
- hanged (吊る)
- full-harness made of rope (ロープで縛る)
- full-harness made of chain
- chained
- crucifixion (磔)
- forniphilia (家具化)
そのほか
- peeing (おしっこ)
- peeing self (おもらし)
- have to pee (おしっこ我慢)
- urinal (男用小便器)
- toilet (トイレ)
- restroom (公衆便所)
- toilet stall
- squat toilet (和式便所)
- pussy juice (愛液)
- cross-section (断面図)
- internal cumshot (オーバーレイ断面図)
- ejaculation, cross-section, x-ray
- mtu virus (立ち絵とスカートの中とを描いたもの)
- loli training wear
- sexy busty female teacher
- vibrator (バイブ)
- artificial vagina (オナホ)
- rainbow colorful luminescence long penis on bonsai (ゲーミングペニス盆栽)
- (ikebana:1.2), (glowing penis:1.3)(ゲーミングチンポ華道部)
解説リンク
絵下手マンがWaifu Diffusionでファンアートを描く方法
続・絵下手マンがWaifu Diffusionでファンアートを描く方法 加筆ノウハウ編
より思い通りの画像を作る!img2img&フォトバッシュ複合ワークフローについて\[StableDiffusion\]
AI画像生成を利用した着色高速化ワークフロー[NovelAI]
画像AIのSDXL+加筆で、手描きに近い白黒漫画を作れないか実験してみた【2】
漫画
漫画未経験のエンジニアが今のAIで漫画制作にトライしてみた記録2023年夏時点版