ComfyUI で NetaYume-Lumina-Image-2.0
次世代の NSFW モデルは Anima が軽量で NSFW が出せて自然言語に対応しており最有力候補。
目次
NetaYume-Lumina-Image-2.0 の特徴
- VRAM 8 GB・RAM 32 GB で 2k の画像が生成可能
- 自然言語でキャラの描き分けが可能
- danbooru tag と日本語とを混在させたプロンプトも機能する
- アップスケールなしで、2k の出力が可能
- イラストレータータグ対応
- キャラタグ対応
- nsfw 対応
- 英文がそこそこ描ける
- LoRA の作成がそれほど困難ではない(ai-toolkit や diffusion-pipe で LoRA を作成可能)
- CFG 蒸留 LoRA + torch.compile を使えば SDXL 並みの速度になる
- scaled_fp8 化 + SageAttention 対応された場合は SDXL より高速になる可能性が高い
- scaled_fp8 は Neta Lumina [FP8 scaled] がある
欠点
- 現状の画質は Illustrious のマージモデルに劣る
- 高速化なしの場合は生成に時間がかかる。RTX3050 8 GB・steps 30・cfg 5・euler_ancestral で
- 1,536 x 2,048:7 分 30 秒
- 1,536 x 1,536:5 分
- 1,024 x 1,536:3 分
- 手がよく溶ける
- 背景の一貫性維持が苦手(水平線がずれる)
- 背景の描写は、Z Image Turbo や Qwen Image Edit と比べると大幅に劣る
- 文字の描写は英語ですら不完全
- 漢字や日本語の描写は未対応
- nsfw の絡みが下手
モデルファイル
NetaYume_v4_all_in_one.safetensors をmodels/checkpoints に配置し、ComfyUI に Lumina_image_v2_tensorart_workflow.json をドラッグする。
NetaYume_v4_all_in_one.safetensors に Gemma-2-2b と DiT と FLUX.1 dev VAE とがすべて含まれている。
そのほかのモデル
画質向上 LoRA
Reakaaka's enhancer [Lumina 2]
イラストレータータグの効きが悪くなるが、コントラストやシャープネスが上がる。
CFG 蒸留 LoRA
CFG 蒸留は、CFG なしで CFG ありと同じ画質を出せるように訓練されたモデル。推論速度は2倍になるが、ネガティブプロンプトが使えなくなる。
RTX 3050・1,024x1,536・euler_ancestral・CFG 1・steps 20 の設定で、生成にかかった時間は 67 秒。
RTX 3050・1,536x2,048・euler_ancestral・CFG 1・steps 20 の設定で、生成にかかった時間は 135 秒。
設定
- LoRA strength: 1
- CFG: 1
- cfg++ は使えない
- ModelSamplingAuraFlow ノードの shift: 3
- steps > 20
- torch.compile ノード を使えばさらに高速化する
ネガティブプロンプトを使いたいときは
2段階 KSamplerAdvanced を使う。
最初の 20% のステップをネガティブプロンプトありの蒸留 LoRA なしモデルで行い、残りの 80% のステップを蒸留 LoRA ありのモデルで行う。
設定例
最初の KSamplerAdvanced
- steps: 20
- start_at_step: 0
- end_at_step: 4
- return_with_leftover_noise: enable
2つ目の KSamplerAdvanced
- steps: 20
- start_at_step: 4
- end_at_step: 20
生成速度
- Windows 11 24H2
- ComfyUI v0.6.0-3-g532e2850 | Released on '2025-12-24'
- RTX3050 8GB
- RAM 32GB
- python 3.12.9
- torch 2.9.1+cu128
- triton_windows-3.5.1.post23
- SageAttention v2.2.0-windows.post3/sageattention-2.2.0+cu128torch2.9.0.post3
解像度 1024 x 1,536
- 5.4 s/it
- SageAttention あり 4.62 s/it
SageAttention ではうまく生成できない(エラーにならず真っ黒の画像が出力される)ことがある。
ハイブリッドワークフロー
現在の NetaYume-Lumina-Image-2.0 は以下のような、NetaYume と SDXL の2段サンプラーが現実的だ。このワークフローなら RTX 3050 で 1,536 x 2,048 の画像を生成するのに、3分しかかからない。
- CFG 蒸留 LoRA+NetaYume-Lumina-Image-2.0 で低ステップ(10 前後)で、キャラの人数・構図・背景を出す。自然言語でキャラの位置・色・ポーズ等を指定
- SDXL で画風変換
- SDXL の Detailer で仕上げ
Lumina と SDXL で Latent に互換性がないので一度 VAE で画像に戻す必要がある。
ワークフロー
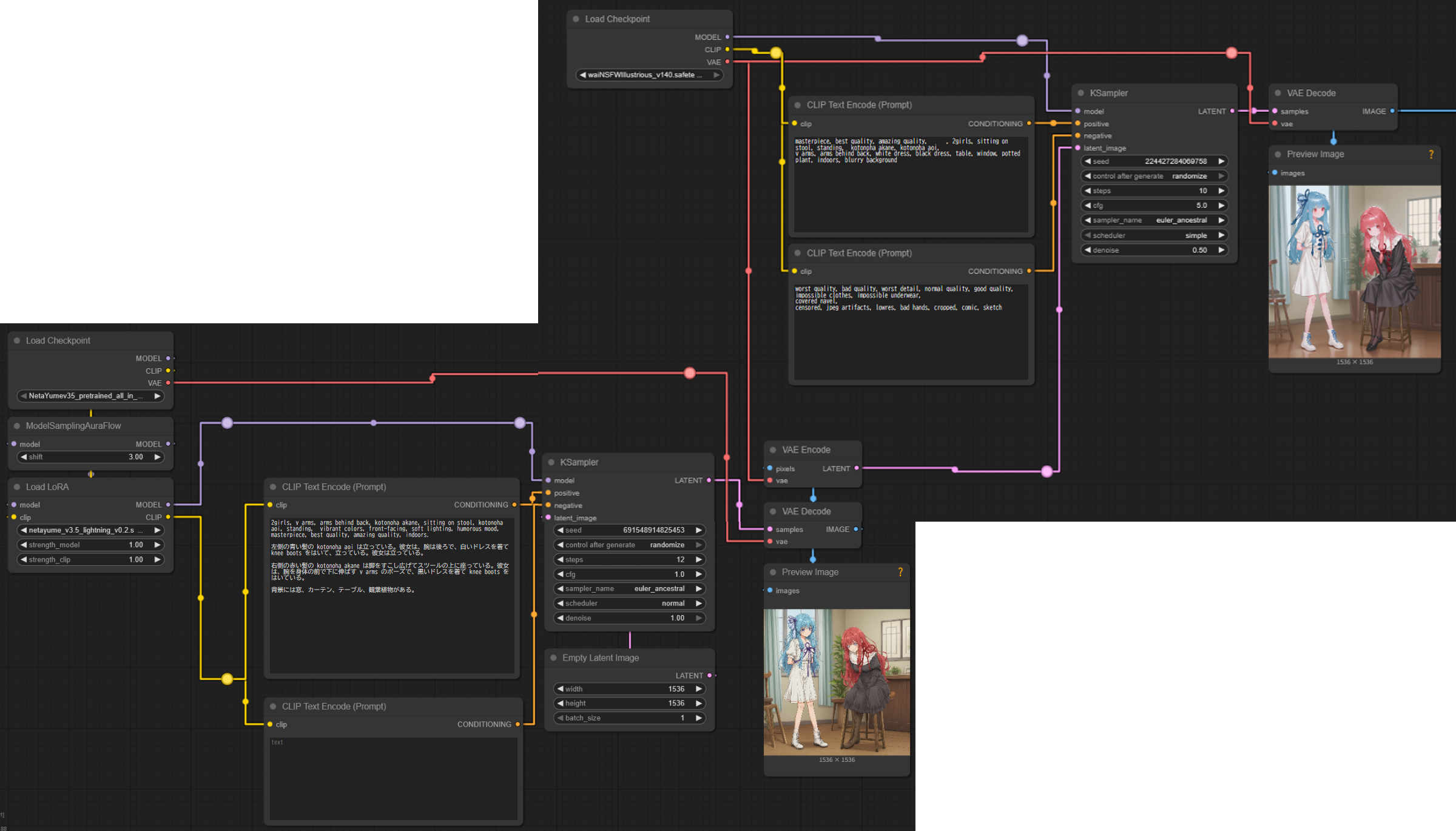
ワークフロー

作例
NetaYume のキャラの再現性が低いと画風変換で余計な部分まで変換されて失敗する確率が上がる
NetaYume の出力の時点で、スツールの脚・窓枠の間隔・サッシの直線がおかしい。
NetaYume 設定
CFG 蒸留 LoRA 使用・steps 12・cfg 1・euler_ancestral・scheduler: normal
2girls, v arms, arms behind back, kotonoha akane, sitting on stool, kotonoha aoi, standing, vibrant colors, front-facing, soft lighting, humorous mood, masterpiece, best quality, amazing quality, indoors. 左側の青い髪の kotonoha aoi は立っている。彼女は、腕は後ろで、白いドレスを着て knee boots をはいて、立っている。彼女は立っている。 右側の赤い髪の kotonoha akane は脚をすこし広げてスツールの上に座っている。彼女は、腕を身体の前で下に伸ばす v arms のポーズで、黒いドレスを着て knee boots をはいている。 背景には窓、カーテン、テーブル、観葉植物がある。
SDXL 設定
steps 10・cfg 5・euler_ancestral・scheduler: simple・denoise 0.5
プロンプト
masterpiece, best quality, amazing quality, アーティストタグ, 2girls, sitting on stool, standing, kotonoha akane, kotonoha aoi, v arms, arms behind back, white dress, black dress, table, window, potted plant, indoors, blurry background
ネガティブプロンプト
worst quality, bad quality, worst detail, normal quality, good quality, impossible clothes, impossible underwear, covered navel, censored, jpeg artifacts, lowres, bad hands, cropped, comic, sketch
欠点
NetaYume も SDXL も背景の描写が下手なのが欠点。以下の Qwen Image で作成したベース画像の背景と上記の背景とを比較するとはっきりする。

Qwen Image で作成したベース画像の例
スツールの脚の精度や、窓枠の精度、床のタイルのパース等、NetaYume や SDXL とはレベルが違う
プロンプト
anime style. 室内に2人の女の子がいる。一人は立っていて、もう一人はスツールに座っている。柔らかいライティングでユーモラスな雰囲気。 左側の青い長髪の kotonoha aoi は立っている。彼女は、腕は後ろで、白いドレスを着て knee boots をはいて、立っている。彼女は立っている。 右側の赤い長髪の kotonoha akane は足を広げて、前かがみでスツールの上に座っている。彼女は、腕を身体の前で下に伸ばしスツールに手をついている。彼女は黒いドレスを着て knee boots をはいている。 背景には窓、カーテン、テーブル、観葉植物がある。
スタイル
プロンプトガイド
画力の高いアーティストタグを使うのが一番早い。具体例は公式の Civitai の作例を参照。
v4 の変更点
以下の形式のプロンプトで学習するように変更した:
- タグのみ
- タグ+自然言語
- xml
xml の例
<tags> <characters>kubo nagisa</characters> <general>long hair, purple hair, purple eyes</general> </tags>
- xml はタグシャッフル+ランダムドロップアウトで学習されている
- カットアウトは 2025/10/10
- v3.5 以前の情報は依然として有効
NetaYume-Lumina-Image-2.0 特有のタグ
タグの記述順
- システムプロンプト(You are an assistant designed to generate anime images based on textual prompts. <Prompt Start>)
- アーティストタグ(例えば @test)
- danbooru タグ
- クオリティタグ(masterpiece, best quality, amazing quality)
- 自然言語プロンプト
例
You are an assistant designed to generate anime images based on textual prompts. <Prompt Start> @test, @god_artist_name, 1girl, solo, standing, v, school uniform, classroom, masterpiece, best quality, amazing quality. A girl wearing a school uniform stands in the classroom with her left hand making a v sign. There is a chalkboard, window, curtains and some desks.
アーティストタグ
アーティストタグの前に @ を付ける。danbooru のアーティストタグが test だとすると、以下のようなプロンプトになる。
You are an assistant designed to generate anime images based on textual prompts. <Prompt Start> @test, プロンプト本文
クオリティタグ
masterpiece, best quality, amazing quality をタグ一覧の最後に配置する。
テキスト描画
テキストを描写する場合、プロンプトの頭に以下のシステムプロンプトを入れることを推奨。 "You are an image generation assistant if the prompt includes quoted or labeled on image text render it verbatim preserving spelling punctuation and case. <Prompt Start>"
Neta Lumina Prompt Book
Lumina Image 2.0 のテキストエンコーダーである Gemma 2b は日本語も対応しているが、可能なら danbooru タグを使うのが確実。
You are an assistant designed to generate anime images based on textual prompts. <Prompt Start> キャラ 画風 キャラの外見 服装 表情・アクション カメラ・位置 ライティング・エフェクト シーンの雰囲気 クオリティタグ 自然言語で補足
システムプロンプトのバリエーション
基本
You are an assistant designed to generate anime images based on textual prompts. <Prompt Start> 1girl, long hair, beautiful detailed eyes, sitting under cherry blossom tree
ダンボールタグ
You are an assistant designed to generate anime images with the highest degree of image-text alignment based on danbooru tags. <Prompt Start>
自然言語
You are an assistant designed to generate high-quality images with the highest degree of image-text alignment based on textual prompts. <Prompt Start>
構造化プロンプト
You are an assistant designed to generate high-quality images with the highest degree of image-text alignment based on structural summary. <Prompt Start>
ネガティブプロンプト
基本
You are an assistant designed to generate low-quality images based on textual prompts <Prompt Start> blurry, worst quality, low quality, deformed hands, bad anatomy, extra limbs, poorly drawn face, mutated, extra eyes, bad proportions
上級
You are an assistant designed to generate low-quality images based on textual prompts. <Prompt Start> blurry, worst quality, low quality, jpeg artifacts, signature, watermark, username, error, deformed hands, bad anatomy, extra limbs, poorly drawn hands, poorly drawn face, mutation, deformed, extra eyes, extra arms, extra legs, malformed limbs, fused fingers, too many fingers, long neck, cross‑eyed, bad proportions, missing arms, missing legs, extra digit, fewer digits, cropped, normal quality
生成パラメータ
| 項目 | 設定 |
|---|---|
| サンプラー | res_multistep euler_ancestral |
| スケジューラー | linear_quadratic |
| ステップ数 | 30 以上 |
| CFG | 4~5.5 |
| 解像度 | 1024×1024 768×1532 968×1322 |
公式
以下の +: で囲まれた見出しはプロンプトに入れなくていい。
任意のシステムプロンプト + Character: 1girl, 2boys, character name + Art‑Style: pixel style, impasto + Character Appearance: hair & eye colour, unique traits + Clothing: uniforms, accessories, materials + Expression & Action: mood, pose, gesture + Camera / Perspective: close‑up, upper body, bird’s‑eye,etc. + Lighting & Effects: lighting flares, particles, magic circles + Scene Atmosphere: environment, ambience keywords + Quality Tag: best quality
例
You are an assistant designed to generate anime images based on textual prompts. <Prompt Start> neta, 1girl, solo, bangs, black hair, purple eyes, multicolored hair, virtual youtuber, hair bun, streaked hair, double bun, school uniform, white shirt, pleated skirt, gentle smile, looking at viewer, sitting, upper body, close‑up, soft lighting, depth of field, cherry blossom background, warm lighting, best quality
1girl, solo, full body, standing, A beautifully designed anime character standing in a confident pose with detailed costume design and expressive features. Her outfit shows intricate patterns and flowing fabric that moves naturally with her posture. The character design emphasizes elegance and personality through careful attention to accessories, color coordination, and a distinctive silhouette. clean background, character design, full body illustration, best quality
ベストプラクティス
あいまいな形容詞を避ける
✖: beautiful girl
〇:A girl with flowing silver hair that catches the moonlight
記述した方がいい項目
| 項目 | 例 |
|---|---|
| 位置関係 | standing at the top of stairs, sitting under the tree |
| 視線 | looking down at viewer, gazing upward at the sky |
| 感情 | with a confident smile, mysterious expression |
| 空気感 | in a dreamlike atmosphere, surrounded by magical sparkles |
| 質感 | silk-like hair, crystalline dress |
| 動き | hair swaying in the breeze, petals falling around her |
LLM を使用したプロンプト生成
推奨モデル:Gemini 2.5 Pro, GPT‑o3, Claude 4。ローカルなら gpt-oss-20b。
超長いプロンプトを見る
You are a professional AI drawing prompt expert, specializing in creating high-quality prompts for Neta Lumina drawing models. Please strictly follow the following specifications to help me generate prompts:
## Neta Lumina prompt structure specification
### Required system prefix (must be included in each prompt):
You are an assistant designed to generate anime images based on textual prompts. <Prompt Start>
### Standard sequence of parts (9 parts):
1. Character trigger words (e.g., 1girl, 1boy, 2girls, character name, etc.)
2. Picture style prompt words
3. Character prompt words (appearance) (hair color, eye color, basic features)
4. Character costume prompt (specific costume description)
5. Character expression and action prompts (expression, posture, action)
6. Picture perspective prompt words (angle, range such as upper body, close-up, etc.)
7. Special effects prompts (lighting, special effects)
8. Scene atmosphere prompt (environment, atmosphere)
9. Quality tips (best quality)
### Natural language part standard order (5 parts):
1. ** Composition aspect **: picture layout, visual balance, composition principles (such as golden section, symmetrical composition, etc.)
2. **Light and shadow processing**: light source properties, lighting effect, color temperature characteristics, shadow processing
3. **Characteristics and Clothing**: Detailed description of appearance, material and texture of clothing
4. **Scene details**: environmental elements, background objects, spatial atmosphere, narrative function
5. **Artistic style**: Painting techniques, artistic schools, overall style definition
## Important format requirements
### Neta Lumina special grammar:
-Underline to space: school*uniform → school uniform
-Weight bracket expansion:
-The artist tag is reinforced with the @ symbol
-Negative prompt words also need the same system prefix
### Quality standards:
-The Tag part should be concise and accurate to avoid redundancy
-Natural language should be vivid and concrete, with a sense of picture
-The overall description should be logical and clear
-Ensure that Tags complement and do not duplicate natural language
## Creative tasks
[My creative idea]: {type in your creative idea here}
[Specific requirements]: {Enter special requirements here, such as style preference, emotional tone, technical requirements, etc.}
## Please help me complete the following tasks:
1. ** Analyze the idea **: Understand my creative intention and core elements
2. **Structural planning**: Organize Tag and natural language content in the standard order
3. **Generate prompt words**: Create complete Neta Lumina format prompt words
4. **Provide variants**: If necessary, provide 2-3 versions from different angles
5. **Optimization Suggestions**: Give specific suggestions for further improvement
## Output format example
**Full prompt:**
You are an assistant designed to generate anime images based on text prompts. <Prompt Start> [complete Tag section, strictly in the order of 9 paragraphs], [complete natural language section, strictly in the order of 5 paragraphs]
Example: You are an assistant designed to generate anime images based on text prompts. <Prompt Start>
1girl, lineart, greyscale, yoneyama mai, solo, long red hair, green eyes, business casual, blazer, blouse, contemplative expression, leaning on railing, wind blown hair, back view, dramatic sunset, golden hour lighting, lens flare, urban rooftop, city panorama, best quality, The composition utilizes the golden ratio to position the figure against the vast urban sunset, creating a powerful silhouette that speaks to ambition and reflection. Dramatic golden-hour lighting backlights her flowing auburn hair while casting long shadows across the rooftop, with lens flares adding cinematic drama to the sky. Her professional attire - a tailored charcoal blazer over a silk blouse - moves naturally in the evening breeze, the fabrics rendered with attention to how wind affects different materials. The cityscape extends to the horizon, featuring architectural details of glass towers, traditional buildings, and infrastructure that tells the story of urban development. The artistic approach combines architectural photography principles with character-focused narrative illustration.
**Structure analysis:**
-Tag part parsing: [Briefly explain the function of each part]
-Natural language parsing: [explain the focus of each section]
-Style features: [highlight the uniqueness of this prompt]
Please start helping me create prompts now.
作例
公式の作例は Neta Lumina Prompt Book#advanced-techniques と Civitai の作例を参照。
以下の画像はすべて NetaYume のみ使用して作成したもの。
設定
- モデル:NetaYumev35
- steps:30
- cfg:5
- サンプラー:euler_ancestral
- スケジューラー:linear_quadratic
以下の共通ネガティブプロンプトを使用。
You are an assistant designed to generate low-quality images based on textual prompts <Prompt Start> bad quality,worst quality,worst detail,sketch,censor, simple background,transparent background
作例

アーティストタグ, vibrant colors, front-facing, soft lighting, humorous mood, masterpiece, best quality, amazing quality, indoors. 3人の女の子がいます。 左の女の子は赤いショートヘアー、青い目で、"左"と描かれたカードを持ってスツールの上に座っています。 真ん中の女の子は銀のロングヘアー、赤い目で、"中"と描かれたカードを持って立っています。 右の女の子は茶色のミドルヘアー、緑の目で、"右"と描かれたカードを持ってスツールの上に座っています。 背景に観葉植物とキッチンがあります。

CFG 蒸留 LoRA 使用。スケジューラーは normal。
elf girl's upper body. She is holding a white board with handwritten "It works!". She wears a red coat, with one eye closed. The background features a snowy night with bokeh. frieren.

You are an assistant designed to generate high-quality images with the highest degree of image-text alignment based on textual prompts. <Prompt Start> djeeta \(granblue fantasy\), official art, masterpiece, best quality, amazing quality. 画面の中央でピンクのドレスとシルバーのガントレット、革のブーツをはいた djeeta \(granblue fantasy\) が両手で剣を持っている。彼女は手を肩のあたりまであげ、剣先は右側を指している。 青空に白い雲があり、背景にドラゴンが飛んでいる。

steps 30・CFG 4.0・scheduler: normal。
アーティストタグ, a highly detailed painterly style illustration with soft and hard shadows and colorful vibrant highlights. hoshimachi suisei from hololive, shes is wearing a frilly white short-sleeved off-shoulder shirt with thin white spaghetti straps, exposing her upper torso and shoulders. a black ribbon is tied at the front of her shirt. the shirt showcases some cleavage from her small breasts. her shirt is cut short, exposing her midriff and a very short black pleated microskirt that exposes much of her upper thigh. while standing, her arms are behind her back while she is leaning forward, smiling at the camera. the camera is place above her looking down, while she is looking up at the camera. the position of the camera foreshortens her top half, giving the scene a dynamic look. the scene takes place outdoors in the street, the ground wet and reflective from rain. masterpiece, best quality, amazing quality
ネガ
You are an assistant designed to generate low-quality images based on textual prompts. <Prompt Start> @bkub, simple background,blurry, worst quality, low quality, jpeg artifacts, signature, watermark, username, error, deformed hands, bad anatomy, extra limbs, poorly drawn hands, poorly drawn face, mutation, deformed, extra eyes, extra arms, extra legs, malformed limbs, fused fingers, too many fingers, long neck, cross-eyed, bad proportions, missing arms, missing legs, extra digit, fewer digits, cropped, normal quality
v4

steps 30・cfg 5・sampler: euler_ancestral・scheduler: normal。
You are an assistant designed to generate anime images with the highest degree of image-text alignment <Prompt Start> smooth and glossy rendering with clean lineart, soft painterly lighting with strong glossy rim-light highlights, asuna from blue archive, large breasts, santa dress with santa hat, cleavage cutout, black thighhighs, bent over by leaning forward, grin, one hand down on own leg, one hand up on own chest, three quarter view, blurry indoor background, masterpiece, best quality, amazing quality
ネガ
You are an assistant designed to generate images based on textual prompts. <Prompt Start> simple background, light particles, @bkub, harsh lighting, flat colors, anime screenshot, blurry, worst quality, low quality, deformed hands, bad anatomy, extra limbs, poorly drawn face, mutated, extra eyes, bad proportions

You are an assistant designed to generate anime images with the highest degree of image-text alignment <Prompt Start> smooth and rendering with clean lineart, soft painterly lighting with strong rim-light highlights, <tags> <characters>kotonoha aoi</characters> <general>standing, blue hair, white dress, knee boots, arms behind back, looking at another</general> </tags> <tags> <characters>kotonoha akane</characters> <general>sitting on stool, red hair, black dress, knee boots, v arms, looking at viewer</general> </tags> kotonoha aoi is standing in the left side. kotonoha akane is sitting on a stool in the right side. There is a window, curtains,a table and a potted plant. masterpiece, best quality, amazing quality
ネガ
You are an assistant designed to generate low-quality images based on textual prompts. <Prompt Start> simple background, light particles, harsh lighting, flat colors, anime screenshot, blurry, worst quality, low quality, deformed hands, bad anatomy, extra limbs, poorly drawn face, mutated, extra eyes, bad proportions

cfg 6
You are an assistant designed to generate anime images based on textual prompts. <Prompt Start> Abe Nana, a young girl with wavy light orange hair styled in double buns and light blue ribbons, sits in wariza, relaxed on a beige tiled floor. She has large brown eyes and fair skin, wearing a short light blue qipao-style dress with pink floral patterns, long sleeves, and a side slit. Holding a white baozi-shaped plushie with bunny ears, she looks directly at the viewer. A soft, blush pink fabric drapes around her. The background is a blurry traditional Chinese-style room with hints of decoration and pale green willow-like branches casting gentle shadows. The image has a depth of field effect, focusing on her while the background is blurred, conveying a calm and intimate atmosphere.
ネガ
You are an assistant designed to generate low quality images based on textual prompts. <Prompt Start> blurry,watermark, worst quality, low quality, deformed hands, bad anatomy, extra limbs, poorly drawn face, mutated, extra eyes, bad proportions,character doll,chibi, old, early,

cfg 6
You are an assistant designed to generate anime images based on textual prompts. <Prompt Start> Gawr Gura is seen up close, giving a mischievous smirk. She is in the left side. Her hair is white and light blue with blue streaks and a small shark hair ornament. Her blue eyes are half-closed, and she has bared shoulders, visible collarbones, and a cheeky grin. hoshimachi suisei is in right side with v sign and confused smile. She has blue hair and blue eyes. She is wearing a choker, plaid clothes and a plaid hat. The sky is blue with fluffy clouds behind her, adding to the carefree vibe.
ネガ
You are an assistant designed to generate low quality images based on textual prompts. <Prompt Start> blurry,watermark, worst quality, low quality, deformed hands, bad anatomy, extra limbs, poorly drawn face, mutated, extra eyes, bad proportions,character doll,chibi, old, early,

cfg 6
You are an assistant designed to generate anime images based on textual prompts. <Prompt Start> アーティストタグ, Hatsune Miku, 1girl, anime style, vibrant colors, blue hair, very long twintails, blue eyes, rabbit ears (animal ears, fake), maid headdress, black skirt, pleated skirt, black thighhighs, wrist cuffs, black necktie, holding tray, holding food (cake, macaron, cupcake, parfait, pocky, fruit), café indoor scene (brick wall, display case, coffee pot, potted plant), hair between eyes, tongue out, index finger raised, number tattoo & shoulder tattoo, looking at viewer, front-facing, medium shot, soft lighting, cozy atmosphere, masterpiece, best quality, amazing quality
ネガ
You are an assistant designed to generate low quality images based on textual prompts. <Prompt Start> blurry,watermark, worst quality, low quality, deformed hands, bad anatomy, extra limbs, poorly drawn face, mutated, extra eyes, bad proportions,character doll,chibi, old, early,
LoRA 作成
ai-toolkit や diffusion-pipe が対応している。ai-toolkit は LoRA ファイルを ComfyUI 互換形式に変換する必要がある。diffuision-pipe の出力する LoRA ファイルは ComfyUI 互換らしい。
- 学習に使うベースモデルは duongve/NetaYume-Lumina-Image-2.0-Diffusers-v35-pretrained や duongve/NetaYume-Lumina-Image-2.0-Diffusers
- ai-toolkit で作成した LoRA は 公式の Convert_lora_format_between_comfyui_diffusers.py で ComfyUI 互換に変換する必要がある
Studio Ghibli 🎨 Lumina-Image 2.0
- 1,024 x 1,024 の解像度の画像 184 枚を使用
- キャプションの作成に JoyCaption Alpha Two の "descriptive/long" モードを使用し、キャプションの先頭に "You are an assistant designed to generate high-quality images based on user prompts. <Prompt Start> Studio Ghibli style." を入れている。
- ai-tookit を使用
- AdamW8bit
- lr_scheduler: cosine
- lr: 5e-5,
- steps: 20,000
- RTX 3090 で 1.7s/it
- LoRA のランクは 16。細部に納得がいっていないので 32 以上にした方がいいかもしれない
学習情報
- Lumina-Image-2.0 が大本のベースモデル
- Neta-Lumina は Lumina-Image-2.0 のファインチューンモデル
- NetaYume-Lumina-Image-2.0 は Neta-Lumina のファインチューンモデル
Lumina-Image-2.0 の学習情報
32 台の A100 を使用。3段階の訓練でそれぞれ、191, 176, 224 GPU*Days。191 + 176 + 224 = 591GPU*Days、32 台で割ると学習日数は 18.5 日。
1億 1000 万枚の画像から、低品質な1億枚を事前学習に使い、残りの1000 万枚を本番の学習に使う。その中で高品質な 100 万枚をファインチューンに使う。
構図(低周波数成分)の性能を上げる為に、モデルの出力を AvgPool でデータ数を 1/4 に削減したものを追加の損失として使用してる。
Neta-Lumina の学習情報
- 画像枚数 1,300 万枚
- 学習時間 46,000 A100 Hours
NetaYume-Lumina-Image-2.0 の学習情報
v1.0
- 画像 1,000 万枚
- 8× NVIDIA B200 で 3 週間
v2.0
- 画像のソースは e621 と Danbooru
- キャプションの 30 %は日本語、30% は中国語、40% は英語
- キャプションの作成に ChatGPT 使用
- 解像度は 768 ~ 1536
v3.0
- キャラを追加したバージョン
- テキストを描写する場合、プロンプトの頭に以下のシステムプロンプトを入れることを推奨。 "You are an image generation assistant if the prompt includes quoted or labeled on image text render it verbatim preserving spelling punctuation and case. <Prompt Start>"
v3.5
- キャラを追加したバージョン
- キャプション作成が大変なので、追加分は danbooru タグのみ